SCARF: Capturing and Animation of Body and Clothing from Monocular Video
项目地址open in new window
Siggraph Asia 2022
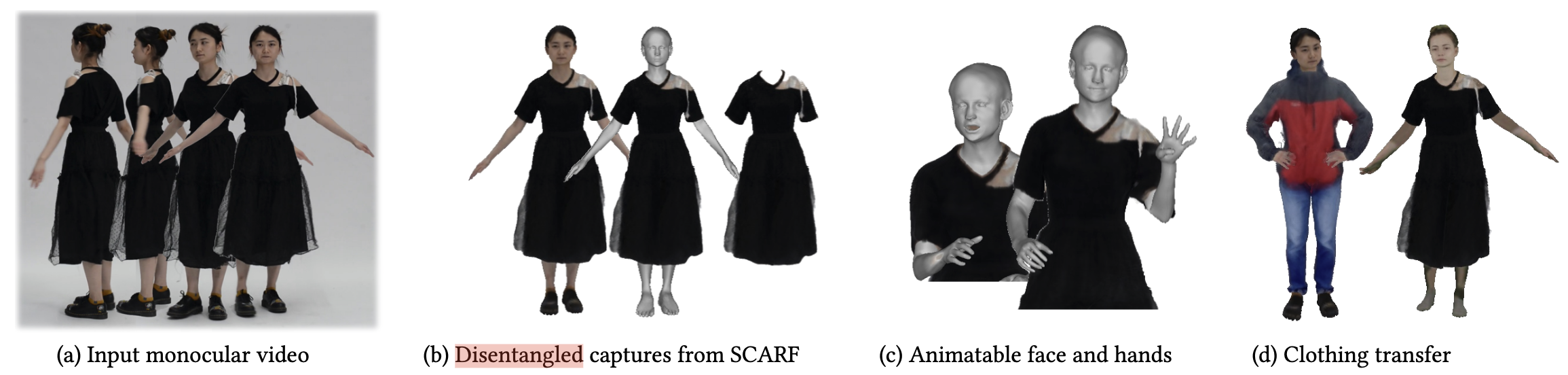 Fig. 1: Overview
Fig. 1: Overview Abstract
尽管最近的研究表明,从单张图像、视频或一组三维扫描图像中提取穿衣三维人体模型的工作取得了进展,但仍存在一些局限性。大多数方法使用整体表示法对身体和服装进行联合建模,这意味着在虚拟试穿等应用中无法将服装和身体分开。其他方法则将人体和服装分开建模,但需要从三维/四维扫描仪或物理模拟中获得的大量三维穿衣人体 mesh 进行训练。我们的见解是,身体和服装有不同的建模要求。基于 mesh 的参数化三维模型可以很好地表示人体,而隐式表示法和神经辐射场则更适合捕捉服装中的各种形状和外观。基于这一观点,我们提出了 SCARF (Segmented Clothed Avatar Radiance Field),这是一种将基于 mesh 的人体与神经辐射场相结合的混合模型。将网格与可微分光栅化器相结合集成到体渲染中,使我们能够直接从单目视频中优化 SCARF,而无需任何 3D 监督。混合建模使 SCARF 能够:(i) 通过改变身体姿势 (包括手部衔接和面部表情) 为穿着衣服的 avatar 制作动画;(ii) 合成 avatar 的新视图;(iii) 在虚拟试穿应用中实现 avatar 之间的服装转移。我们证明,与现有方法相比,SCARF 重建的服装具有更高的视觉质量,服装会随着身体姿势和体形的变化而变形,而且服装可以在不同的 avatar 之间成功转移。
Introduction
概括来说,本文使用 SMPL-X 来表示人体,使用 NeRF 来表示衣服。分为四步:
- NeRF 表示的是标准空间中的衣服,所以首先要估计图片中的人体的 pose,用估计出来的参数将观测空间中衣服的点变换到标准空间。估计 pose 用的 PIXIE 的方法,但是不精确,作者对其进行了优化;
- SMPL-X 的参数无法精确适用于服装的变换,因此本文还学习了一个非刚体变换场来修正服装与身体的偏差;
- 渲染的时候需要考虑到服装和人体的遮挡,所以作者写了一个自己的体渲染方法;
- 要想将身体和衣服分开,必须防止 NeRF 捕捉到包括身体在内的所有图像信息。作者使用衣服分割 mask 来惩罚衣服以外的区域;
Method
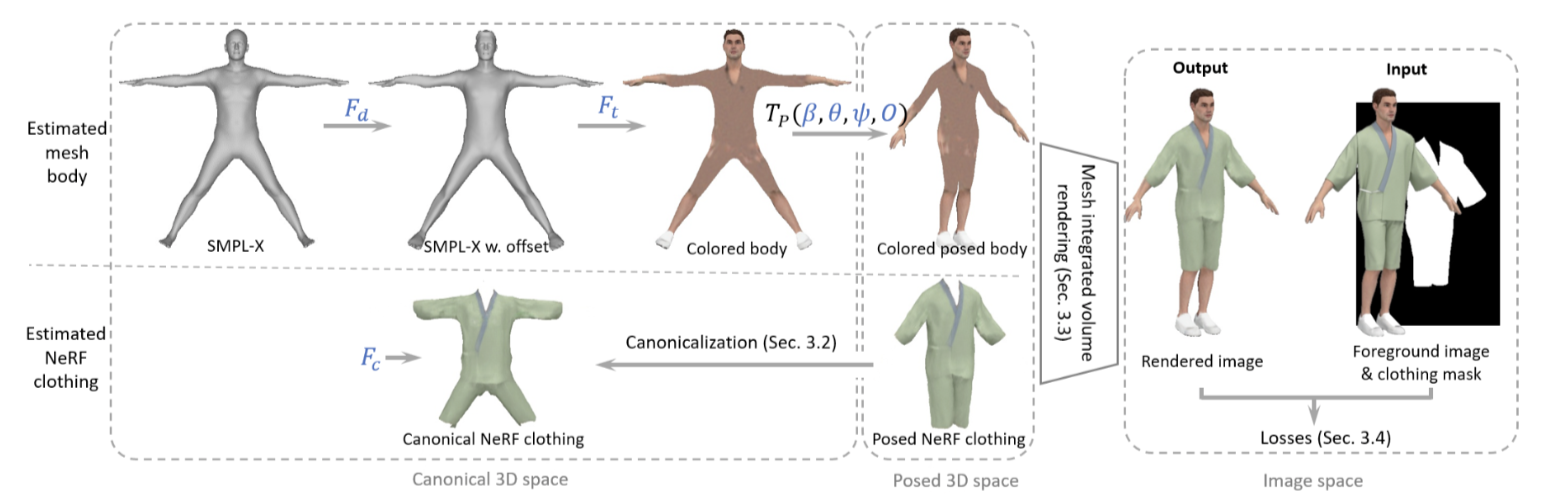 Fig. 2: Pipeline
Fig. 2: Pipeline 混合表示 (Hybrid Representation)
身体表示 (Body representation):模型定义如下:
M(β,θ,ψ,O)=LBS(TP(β,θ,ψ,O),J(β),θ,W)(1)
- β∈R∣β∣ 是 SMPL-X 的 shape 参数
- θ∈R3nk+3 是 SMPL-X 的 pose 参数,nk 表示关节点的数量
- ψ∈R∣ψ∣ 是 SMPL-X 的 facial 参数
- O∈Rnv×3 是一组捕获局部几何细节的顶点位移,nv 表示顶点数量
- J(⋅)∈Rnk×3 表示关节点的回归器
- W∈Rnk×nv 表示 LBS 的权重
公式 (1) 中的 TP(⋅) 定义如下:
TP(β,θ,ψ,O)=T+O+B(β,θ,ψ)(2)
- T∈Rnv×3 是 SMPL-X 在 rest pose 下的模板
- B(β,θ,ψ)=BS(β;S)+BP(θ;P)+BE(ψ;E) 分别表示基于体格的混合形状函数,基于姿态的混合形状函数和基于表情的混合形状函数
最终 vi=Mi(β,θ,ψ,O)ti (vi 和 ti 都是齐次坐标),Mi(⋅)∈R4×4 为:
Mi(β,θ,ψ,O)=(k=1∑nkwk,iGk(θ,J))[I0Toi+Bi(β,θ,ψ)1](3)
- Gk(θ,J)∈R4×4 表示关节 k 在世界坐标系下的变换矩阵
- oi 和 Bi(⋅) 分别是 O 和 B(⋅) 的元素
为了获取更多的几何细节,对 SMPL-X 进行上采样,得到 nv=38705 (论文里是 38703,但实际上是 38705) 个顶点和 nt=77336 个面片。上采样的算法如下:
- 首先将 SMPL-X 的模板转换为四边形的版本
- 然后利用每个四边形的重心坐标,对模板的参数也进行上采样
上采样后还是用三角 mesh 来表示模型,四边形的版本只是用来上采样。为了增加模型的可变形,还要学习一个位移,分别用两个隐式模型 Fd:t→o 和 Ft:t→c 来预测模板 T 上每个顶点 t 的位移和颜色。
服装表示 (Clothing representation):用 NeRF Fc:xc→(c,σ) 表示标准空间下的服装,本文只用 NeRF 表示衣服,不表示人体的部分。但是 SMPL 模型并没有穿着衣服,所以对于衣服在不同 pose 下的变形还需要学习一个标准空间中的 MLP Fm:R6→R3 来表示一个非刚体形变:
Fm(xc,vnn(x)p)→dc(4)
- xc 表示标准空间的一个点
- x 表示观测空间衣服上的一个点
- vnn(x)p 表示观测空间的人体表示中与 x 最近的那个点
预测结果 dc 是偏移量,因此最后输入 Fc 的是 xc+dc。
标准化 (Canonicalization)
使用基于 SMPL-X 模型的逆变换,将模型从观测空间变换到标准空间。公式 3 只是适用于人体表面上的点,下面这个公式可以拓展到整个空间中的点。给出一个人体 mesh M(β,θ,ψ,O)→V 和观测空间中的一个点 x,可以将 x 变换到标准空间:
vi∈N(x)∑ω(x)ωi(x)Mi(0,θc,0,0)(Mi(β,θ,ψ,O))−1x→xc(5)
其中:
ωi(x)=exp(−2σ2∣∣x−vi∣∣2∣∣wnn(x)−wi∣∣2)ω(x)=vi∈N(x)∑ωi(x)(6)
- N(x) 表示在 V 中距离 x 最近的点集,V 表示观测空间中 body mesh 的点集
- wi 表示 vi 的混合蒙皮权重
- σ 是个恒定的权重
损失函数
重建损失:
Lrecon=λvolLδ(Rv−I)+λmrfLmrf(Rv−I)(7)
- Rv 和 I 分别表示渲染出来的图像和 GT
- Lδ 和 Lmrf 分别表示 Huber 损失和 ID-MRF 损失
Huber 损失和 ID-MRF 损失分别是用来约束整体和细节部分的重建效果。
衣服 segentation 的损失:
Lclothing=λclothing∣∣Sv−Sc∣∣1(8)
- Sv 和 Sc 分别表示 NeRF mask 和 GT 的衣服 mask
确保 NeRF 只表示衣服的部分。
人体损失:
穿衣人体 mask 损失:
Lsihouette=λsilhouetteLδ(Rms(M,p)−S)(9)
- Rms(M,p) 表示渲染后的穿衣人体 mask
- S 表示 GT 的穿衣人体 mask
人体 mask 损失:
Lbodymask=λbodymaskLδ(Sb⊙(Rms(M,p)−Sb))(10)
人体光度损失:
Lskin=λskinLδ(Sb⊙(Rm(M,c,p)−I))(11)
- Rm(M,c,p) 表示渲染后穿衣人体的图像
(10) 和 (11) 两个 loss 是为了解决更换人体时出现的瑕疵(特别是宽松的衣服)。
人体范围损失:
Linside=λinsideLδ(ReLU(Rms(M,p)−Sc))(12)
约束人体的范围在衣服 mask 以内
皮肤颜色损失:
Lskininside=λskininsideLδ(Sc⊙(Rm(M,c,p)−Chand))(13)
- Chand 表示人手上顶点的颜色均值
约束被衣服遮挡部分人体和手之间的颜色
正则化:
Lreg=λedgeLedge(M)+λoffset∣∣O∣∣2(14)
- Ledge 表示有偏移和没有偏移的优化身体 mesh 之间的相对边缘损失
所以人体损失表示为:Lbody=Lsihouette+Lbodymask+Lskin+Lskininside+Linside+Lreg
整体的损失函数为:L=Lrecon+Lclothing+Lbody
Reference
[1]Capturing and Animation of Body and Clothing from Monocular Videoopen in new window
[2]哈达玛积open in new window