LayGA: Layered Gaussian Avatars for Animatable Clothing Transfer 项目地址open in new window
SIGGRAPH 2024
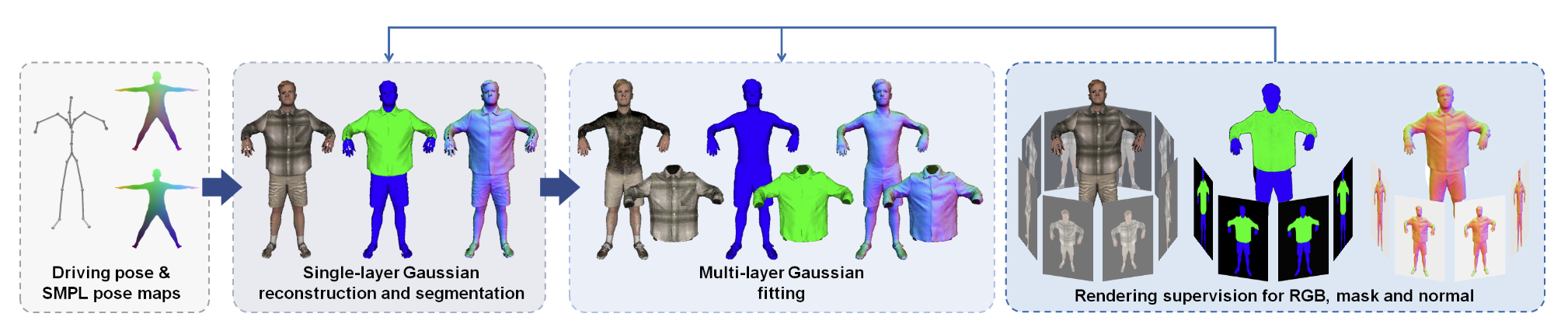
Fig. 1: Overview Abstract 可动画服装转移,旨在不角色间转移服装并对服装进行动画,是一个具有挑战性的问题。大多数数字人工作将人体和服装的表示统一在一起,这导致在不同身份之间的虚拟试衣变得困难。更糟的是,统一的表示通常无法准确跟踪服装的滑动。为了解决这些限制,本文提出了分层高斯数字人 (Layered Gaussian Avatars, LayGA) ,这是一种新的表示方法,将身体和服装分为两个独立的层,用于从多视角视频中实现逼真的可动画服装转移。本文的表示方法基于高斯图数字人,因为它在服装细节的表示能力上非常出色。然而,高斯图会在实际表面周围产生非结构化的 3D 高斯分布。缺乏平滑的显式表面在准确的服装跟踪和处理身体与服装之间的碰撞时带来了挑战。因此,本文提出了两阶段训练方法,包括单层重建和多层拟合。在单层重建阶段,本文提出了一系列几何约束来重建平滑表面,同时获得身体和服装之间的分割。接下来,在多层拟合阶段,本文训练两个独立的模型来表示身体和服装,并利用重建的服装几何形状作为三维监督,以实现更准确的服装跟踪。此外,本文提出了几何和渲染层,用于高质量的几何重建和高保真渲染。总体而言,LayGA 实现了逼真的动画和虚拟试穿,并优于其他 baseline 方法。
Introduction 本文将身体和服装分为两个独立的层,但是直接学习两组高斯来分别表示身体和衣服是不可行的。因为 3DGS 通常在表面上分布不均匀,无法为区分出人体和衣服,而这对于服装适应不同体型和处理衣服和人体的碰撞是很重要的。因此本文提出了两阶段训练方法,包括单层重建和多层拟合。在单层重建阶段,提出了一系列的几何约束来强制 3D 高斯生成在平滑的表面上。最后还提出额外的渲染层来保证平滑重建的同时实现高保真的渲染,因为通过几何约束获得的平滑表面可能会限制渲染的质量。
本文的创新点:
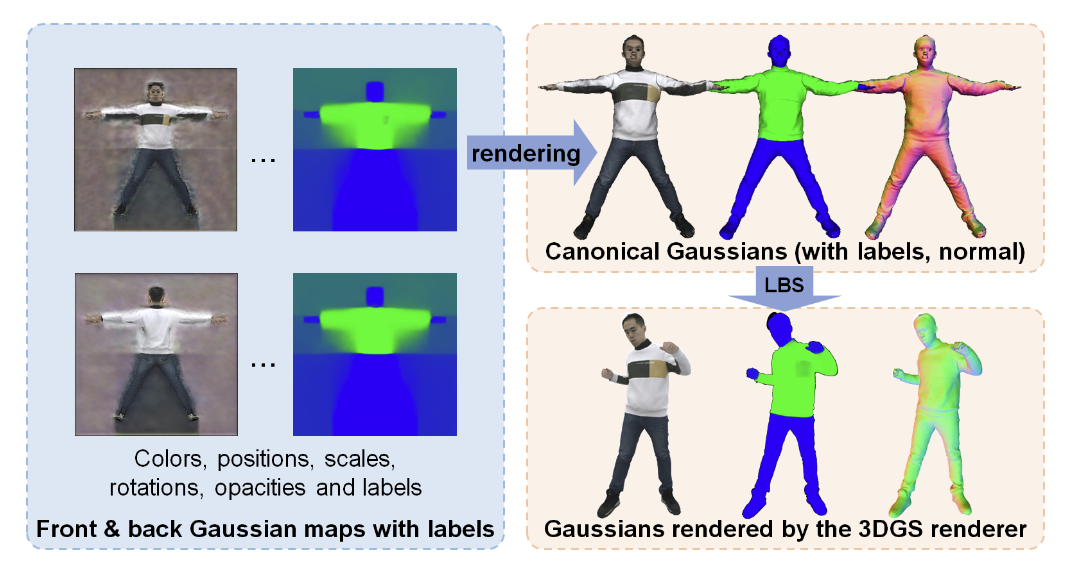
提出了分层高斯数字人 (LayGA),这是首个基于 3DGS 的分层数字人表示法,用于可动画的服装转移。 在 3D 高斯上引入了几何约束,以实现平滑的表面重建,并支持在分层表示中处理人体与服装之间的碰撞。 在多层学习中,引入了先前的衣服的分割作为监督,以便更准确地跟踪服装边界。此外,还引入了一个渲染层,以缓解几何限制带来的渲染质量下降问题。 Method Fig. 2: Pipeline Clothing-aware Avatar Representation Fig. 3: Illustration of the clothing-aware avatar representation 这篇文章是基于 Animatable Gaussians 做的,通过预测二维的 pose 相关高斯图来创建高保真的数字人。本文的服装感知数字人表示 (图 3) 就是在其 pose 相关高斯图上对做了针对性修改。
先学习 position map,然后再用 StyleUNet 学习 Gaussian map 的过程和 Animatable Gaussians 是一样的,这篇文章的创新是除了高斯的基本参数外,额外多学习一个 label 用来区分这个高斯是属于身体还是衣服。
本文的高斯参数为:
c i ∈ R 3 c_i\in\R^3 c i ∈ R 3 Δ x ˉ i ∈ R 3 \Delta\bar{x}_i\in\R^3 Δ x ˉ i ∈ R 3 o i ∈ R o_i\in\R o i ∈ R s ˉ i ∈ R 3 \bar{s}_i\in\R^3 s ˉ i ∈ R 3 q ˉ i ∈ R 4 \bar{q}_i\in\R^4 q ˉ i ∈ R 4 p i c l o t h p_i^{cloth} p i c l o t h p i b o d y p_i^{body} p i b o d y 最终 3D 高斯的均值和协方差为:
x ˉ i = x ˉ i s m p l + Δ x ˉ i (1) \bar{x}_i=\bar{x}_i^{smpl}+\Delta\bar{x}_i \tag{1} x ˉ i = x ˉ i s m pl + Δ x ˉ i ( 1 )
x ˉ i s m p l \bar{x}_i^{smpl} x ˉ i s m pl i i i x i = R i ( θ ) x ˉ i + t i ( θ ) (2) x_i=R_i(\theta)\bar{x}_i+t_i(\theta) \tag{2} x i = R i ( θ ) x ˉ i + t i ( θ ) ( 2 )
Σ i = R i ( θ ) Σ ˉ i R i ( θ ) T (3) \Sigma_i=R_i(\theta)\bar{\Sigma}_iR_i(\theta)^T \tag{3} Σ i = R i ( θ ) Σ ˉ i R i ( θ ) T ( 3 )
R ( θ ) R(\theta) R ( θ ) t ( θ ) t(\theta) t ( θ ) θ \theta θ Σ ˉ i \bar{\Sigma}_i Σ ˉ i s ˉ i \bar{s}_i s ˉ i q ˉ i \bar{q}_i q ˉ i Single-Layer Modeling with Geometric Constraints 在单层重建阶段,目标是训练一个模型,生成平滑分布在人体实际几何表面上的 3D 高斯,并同时获得人体和衣服之间的分割。
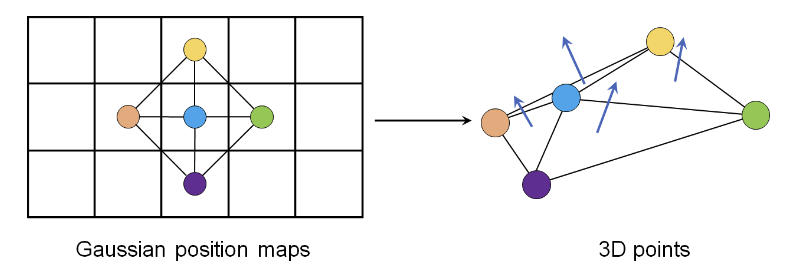
Geometric Constraints for Reconstruction 本文希望重建的穿衣人体表面是连续、平滑的,具有服装细节和清晰的服装边界。通过 2D 高斯图上均匀分布的像素映射为 3D 高斯 ,因此可以方便地使用每个像素的邻域来约束底层几何。具体来说,本文通过一些几何约束来正则化并提高细节。
Image-based Normal Loss . 使用法向量作为额外的监督信号,使用图片中的像素和其相邻像素来获取法向量。如图 4 所示,对于每个像素 i i i j , k , l , m j,k,l,m j , k , l , m n i n_i n i
n i = R i ( θ ) n ˉ i / ∥ R i ( θ ) n ˉ i ∥ 2 , n ˉ i = n ^ i / ∥ n ^ i ∥ 2 (4) n_i= R_i(\theta) \bar{n}_i /\left\|R_i(\theta) \bar{n}_i\right\|_2, \quad \bar{n}_i=\hat{n}_i /\left\|\hat{n}_i\right\|_2 \\ \tag{4} n i = R i ( θ ) n ˉ i / ∥ R i ( θ ) n ˉ i ∥ 2 , n ˉ i = n ^ i / ∥ n ^ i ∥ 2 ( 4 )
n ^ i = ( x ˉ j − x ˉ i ) × ( x ˉ k − x ˉ i ) + ( x ˉ k − x ˉ i ) × ( x ˉ l − x ˉ i ) + ( x ˉ l − x ˉ i ) × ( x ˉ m − x ˉ i ) + ( x ˉ m − x ˉ i ) × ( x ˉ j − x ˉ i ) (5) \hat{n}_i=\left(\bar{x}_j-\bar{x}_i\right) \times\left(\bar{x}_k-\bar{x}_i\right)+\left(\bar{x}_k-\bar{x}_i\right) \times\left(\bar{x}_l-\bar{x}_i\right)\\ +\left(\bar{x}_l-\bar{x}_i\right) \times\left(\bar{x}_m-\bar{x}_i\right)+\left(\bar{x}_m-\bar{x}_i\right) \times\left(\bar{x}_j-\bar{x}_i\right) \tag{5} n ^ i = ( x ˉ j − x ˉ i ) × ( x ˉ k − x ˉ i ) + ( x ˉ k − x ˉ i ) × ( x ˉ l − x ˉ i ) + ( x ˉ l − x ˉ i ) × ( x ˉ m − x ˉ i ) + ( x ˉ m − x ˉ i ) × ( x ˉ j − x ˉ i ) ( 5 )
x ˉ i \bar{x}_i x ˉ i i i i n ^ i \hat{n}_i n ^ i n ˉ i \bar{n}_i n ˉ i n i n_i n i
当计算法向量时,只考虑向量像素都在模版内的像素点。最终的 L n o r m l \mathcal{L}_{norml} L n or m l L 1 L_1 L 1
Fig. 4: Illustration of normal computation on the Gaussian map Stitching Loss . 由于本文的 3D 高斯是在两个独立的 map 上进行参数化的,因此引入了 L s t i t c h \mathcal{L}_{stitch} L s t i t c h L 2 L_2 L 2
Regularization . 和 Animatable Gaussians 一样加了一个 offset 正则化损失 L o f f = 1 N ∑ i ∣ ∣ Δ x ˉ ∣ ∣ 2 2 \mathcal{L}_{off}=\frac{1}{N}\sum_i||\Delta\bar{x}||_2^2 L o ff = N 1 ∑ i ∣∣Δ x ˉ ∣ ∣ 2 2 总变化 (total variational, TV) 损失 L T V \mathcal{L}_{TV} L T V L 2 L_2 L 2 L e d g e L_{edge} L e d g e L e d g e L_{edge} L e d g e 𝐿 2 𝐿_2 L 2
最终几何损失函数为:
L r e g = λ o f f L o f f + λ T V L T V + λ e d g e L e d g e L g e o m = λ n o r m a l L n o r m a l + λ s t i t c h L s t i t c h + L r e g (6) \mathcal{L}_{reg}=\lambda_{off}\mathcal{L}_{off}+\lambda_{TV}\mathcal{L}_{TV}+\lambda_{edge}\mathcal{L}_{edge}\\ \mathcal{L}_{geom}=\lambda_{normal} \mathcal{L}_{normal}+\lambda_{stitch} \mathcal{L}_{stitch}+\mathcal{L}_{reg} \tag{6} L re g = λ o ff L o ff + λ T V L T V + λ e d g e L e d g e L g eo m = λ n or ma l L n or ma l + λ s t i t c h L s t i t c h + L re g ( 6 )
Clothing Segmentation 上文提到会学习一个 label 用来区分这个高斯是属于身体还是衣服,即预测概率 p i b o d y p_i^{body} p i b o d y p i c l o t h p_i^{cloth} p i c l o t h S S S S b o d y S^{body} S b o d y S c l o t h S^{cloth} S c l o t h L l a b e l \mathcal{L}_{label} L l ab e l S S S S g t S_{gt} S g t
L l a b e l = − 1 N b o d y ∑ i log ( S i b o d y ) − 1 N c l o t h ∑ i ′ log ( S i ′ c l o t h ) − 1 N b g ∑ i ′ ′ log ( 1 − S i ′ ′ b o d y − S i ′ ′ c l o t h ) (7) \begin{aligned} \mathcal{L}_{ {label }}= & -\frac{1}{N_{ {body }}} \sum_i \log \left(S_i^{ {body }}\right)-\frac{1}{N_{ {cloth }}} \sum_{i^{\prime}} \log \left(S_{i^{\prime}}^{ {cloth }}\right) \\ & -\frac{1}{N_{ {bg }}} \sum_{i^{\prime \prime}} \log \left(1-S_{i^{\prime \prime}}^{ {body }}-S_{i^{\prime \prime}}^{ {cloth }}\right) \end{aligned} \tag{7} L l ab e l = − N b o d y 1 i ∑ log ( S i b o d y ) − N c l o t h 1 i ′ ∑ log ( S i ′ c l o t h ) − N b g 1 i ′′ ∑ log ( 1 − S i ′′ b o d y − S i ′′ c l o t h ) ( 7 )
i , i ′ , i ′ ′ i,i',i'' i , i ′ , i ′′ S g t S_{gt} S g t N b o d y , N c l o t h , N b g N_{body},N_{cloth},N_{bg} N b o d y , N c l o t h , N b g S g t S_{gt} S g t 如果像素的值在数据集自带的二进制 mask 中是无效的,则它被视为背景; 如果像素被 SCHP 标记为背景,则被视为未确定; 如果像素被 SCHP 标记为非上衣,则被视为身体; 否则,该像素被视为服装; 和几何约束一样,也对 Gaussian label map 加了一个 L 1 L_1 L 1 L T V l a b e l \mathcal{L}_{TV}^{label} L T V l ab e l L s t i t c h l a b e l \mathcal{L}_{stitch}^{label} L s t i t c h l ab e l
L s e g = λ l a b e l L l a b e l + λ T V l a b e l L T V l a b e l + λ s t i t c h l a b e l L s t i t c h l a b e l (8) \mathcal{L}_{ {seg }}=\lambda_{ {label }} \mathcal{L}_{ {label }}+\lambda_{\mathrm{TV}}^{ {label }} \mathcal{L}_{\mathrm{TV}}^{ {label }}+\lambda_{ {stitch }}^{ {label }} \mathcal{L}_{ {stitch }}^{ {label }} \tag{8} L se g = λ l ab e l L l ab e l + λ TV l ab e l L TV l ab e l + λ s t i t c h l ab e l L s t i t c h l ab e l ( 8 )
渲染损失函数为:
L r e n d e r = λ L 1 L L 1 + λ s s i m L s s i m + λ l p i p s L l p i p s (9) \mathcal{L}_{ {render }}=\lambda_{\mathrm{L} 1} \mathcal{L}_{\mathrm{L} 1}+\lambda_{ {ssim }} \mathcal{L}_{ {ssim }}+\lambda_{ {lpips }} \mathcal{L}_{ {lpips }} \tag{9} L re n d er = λ L 1 L L 1 + λ ss im L ss im + λ lp i p s L lp i p s ( 9 )
最后总的损失函数为:
L = L r e n d e r + L g e o m + L s e g (10) \mathcal{L}=\mathcal{L}_{render}+\mathcal{L}_{geom}+\mathcal{L}_{seg} \tag{10} L = L re n d er + L g eo m + L se g ( 10 )
Avatar Fitting with Multi-Layer Gaussian 多层建模阶段的目标是使用单层阶段分割出来的衣服的几何来构建双层的数字人。分割的标准是 p c l o t h > 0.5 p^{cloth}>0.5 p c l o t h > 0.5
Separating Geometry and Rendering Layers 前文中加了几何约束来使 3D 高斯汇聚成一个平滑的表面,但是这些几何限制对 3DGS 的渲染质量产生了负面影响,可能是因为这些几何限制降低了高斯在高保真外观建模方面的灵活性。为了降低这些负面影响并保持光滑的几何表面,本文提出将几何层和渲染层分开。如图 5 所示,除了前面提到的 Δ x ˉ i \Delta\bar{x}_i Δ x ˉ i Δ y ˉ i \Delta\bar{y}_i Δ y ˉ i
y i = R i ( θ ) ( x ˉ i s m p l + Δ x ˉ i + Δ y ˉ i ) + t i ( θ ) (11) y_i=R_i(\theta)(\bar{x}_i^{smpl}+\Delta\bar{x}_i+\Delta\bar{y}_i)+t_i(\theta) \tag{11} y i = R i ( θ ) ( x ˉ i s m pl + Δ x ˉ i + Δ y ˉ i ) + t i ( θ ) ( 11 )
Fig. 5: Illustration of geometric and rendering layers. 𝜖 is the threshold for handling collisions. 为了约束身体层使其位于衣服层的里面,在身体几何层和衣服几何层之间施加了一个碰撞损失:
L c o l l = 1 N c l o t h ∑ i max ( ϵ − d i , 0 ) 2 , where d i = ( x ˉ i c l o t h − x ˉ i b o d y ) ⋅ n ˉ i b o d y (12) \mathcal{L}_{coll}=\frac{1}{N_{cloth}}\sum_i\max(\epsilon-d_i,0)^2,\ \text{where} \ \ d_i=(\bar{x}_i^{cloth}-\bar{x}_i^{body})\cdot\bar{n}_i^{body} \tag{12} L co ll = N c l o t h 1 i ∑ max ( ϵ − d i , 0 ) 2 , where d i = ( x ˉ i c l o t h − x ˉ i b o d y ) ⋅ n ˉ i b o d y ( 12 )
ϵ \epsilon ϵ i i i 只是处理身体几何层和衣服几何层之间的碰撞无法保证对应的渲染层之间没有碰撞,因此对渲染层增加一个约束,确保渲染层贴近几何层:
L l a y e r = 1 N b o d y ∑ i max ( ∥ Δ y ˉ i b o d y ∥ 2 − ϵ / 2 , 0 ) 2 + 1 N c l o t h ∑ i ′ max ( ∥ Δ y ˉ i ′ c l o t h ∥ 2 − ϵ / 2 , 0 ) 2 . (13) \begin{aligned} \mathcal{L}_{ {layer }}= & \frac{1}{N_{ {body }}} \sum_i \max \left(\left\|\Delta \bar{y}_i^{ {body }}\right\|_2-\epsilon / 2,0\right)^2 \\ & +\frac{1}{N_{ {cloth }}} \sum_{i^{\prime}} \max \left(\left\|\Delta \bar{y}_{i^{\prime}}^{ {cloth }}\right\|_2-\epsilon / 2,0\right)^2 . \end{aligned} \tag{13} L l a yer = N b o d y 1 i ∑ max ( Δ y ˉ i b o d y 2 − ϵ /2 , 0 ) 2 + N c l o t h 1 i ′ ∑ max ( Δ y ˉ i ′ c l o t h 2 − ϵ /2 , 0 ) 2 . ( 13 )
L c o l l \mathcal{L}_{coll} L co ll ϵ \epsilon ϵ L c l o t h \mathcal{L}_{cloth} L c l o t h ϵ / 2 \epsilon/2 ϵ /2
Geometric Supervision from Reconstructions 由于仅使用图像监督来跟踪服装边界比较困难,因此本文在这一阶段通过在服装几何层和分割后的服装重建之间使用倒角距离 (Chamfer distance, CD) 损失来直接监督服装的运动:
c d = ChamferDist ( { x i c l o t h } i , { x i r e c o n } i ) (14) \mathcal{cd}=\text{ChamferDist}(\{x_i^{cloth}\}_i,\{x_i^{recon}\}_i) \tag{14} c d = ChamferDist ({ x i c l o t h } i , { x i reco n } i ) ( 14 )
{ x i c l o t h } i , { x i r e c o n } i \{x_i^{cloth}\}_i,\{x_i^{recon}\}_i { x i c l o t h } i , { x i reco n } i Segmentation Loss 在本阶段,分割的概率会直接设置为 1 1 1 0 0 0 L r e g \mathcal{L}_{reg} L re g L l a b e l \mathcal{L}_{label} L l ab e l
L = L r e n d e r + L g e o m + λ l a b e l L l a b e l + λ c o l l L c o l l + λ l a y e r L l a y e r + λ c d L c d (15) \mathcal{L}=\mathcal{L}_{ {render }}+\mathcal{L}_{ {geom }}+\lambda_{ {label }} \mathcal{L}_{ {label }}+\lambda_{ {coll }} \mathcal{L}_{ {coll }}+\lambda_{ {layer }} \mathcal{L}_{ {layer }}+\lambda_{ {cd }} \mathcal{L}_{\mathrm{cd}} \tag{15} L = L re n d er + L g eo m + λ l ab e l L l ab e l + λ co ll L co ll + λ l a yer L l a yer + λ c d L cd ( 15 )
Todo
本文最后还有一个 Animatable Clothing Transfer and Collision Handling 章节,用于在不同角色之间转移服装并处理碰撞,暂时先跳过。
Reference [1]LayGA: Layered Gaussian Avatars for Animatable Clothing Transferopen in new window