Learning Implicit Templates for Point-Based Clothed Human Modeling 项目地址open in new window
ECCV 2022
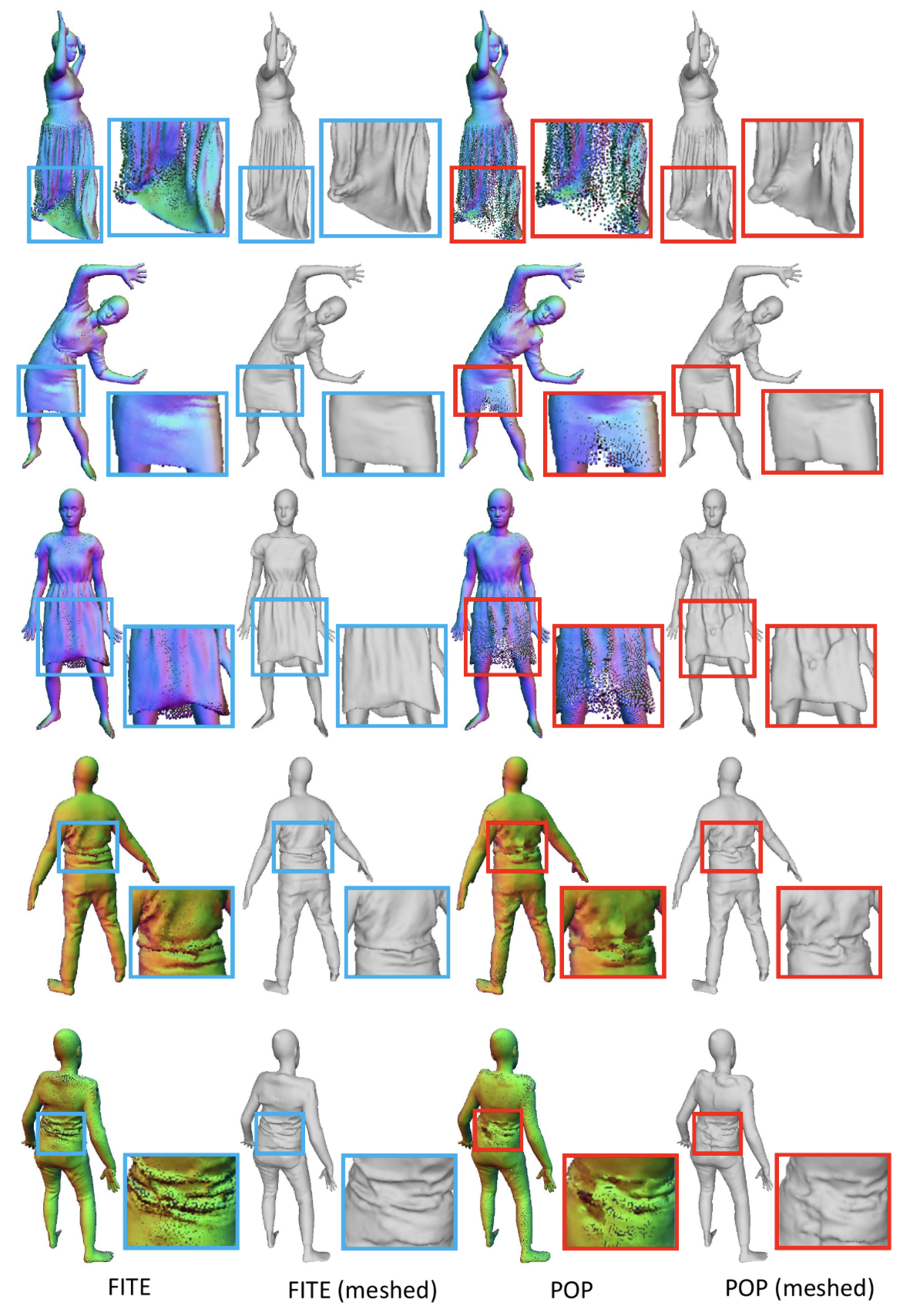
Fig. 1: Overview Abstract 我们提出的 FITE (First-Implicit-Then-Explicit) 是一个先隐后显的框架,用于为穿着服装的数字人建模。我们的框架首先学习表示粗略服装拓扑结构的隐式表面模板,然后利用模板指导点集的生成,进一步捕捉与姿势相关的服装变形(如褶皱)。我们的管道结合了隐式和显式表示法的优点,即能够处理不同的拓扑结构,并能有效捕捉精细细节。我们还提出了扩散蒙皮技术,以方便模板训练,尤其是宽松服装的模板训练,以及通过基于投影的 pose 编码从 mesh 模板中提取 pose 信息,而无需预定义的 UV 贴图或连通性。
Introduction 本文的主要贡献:
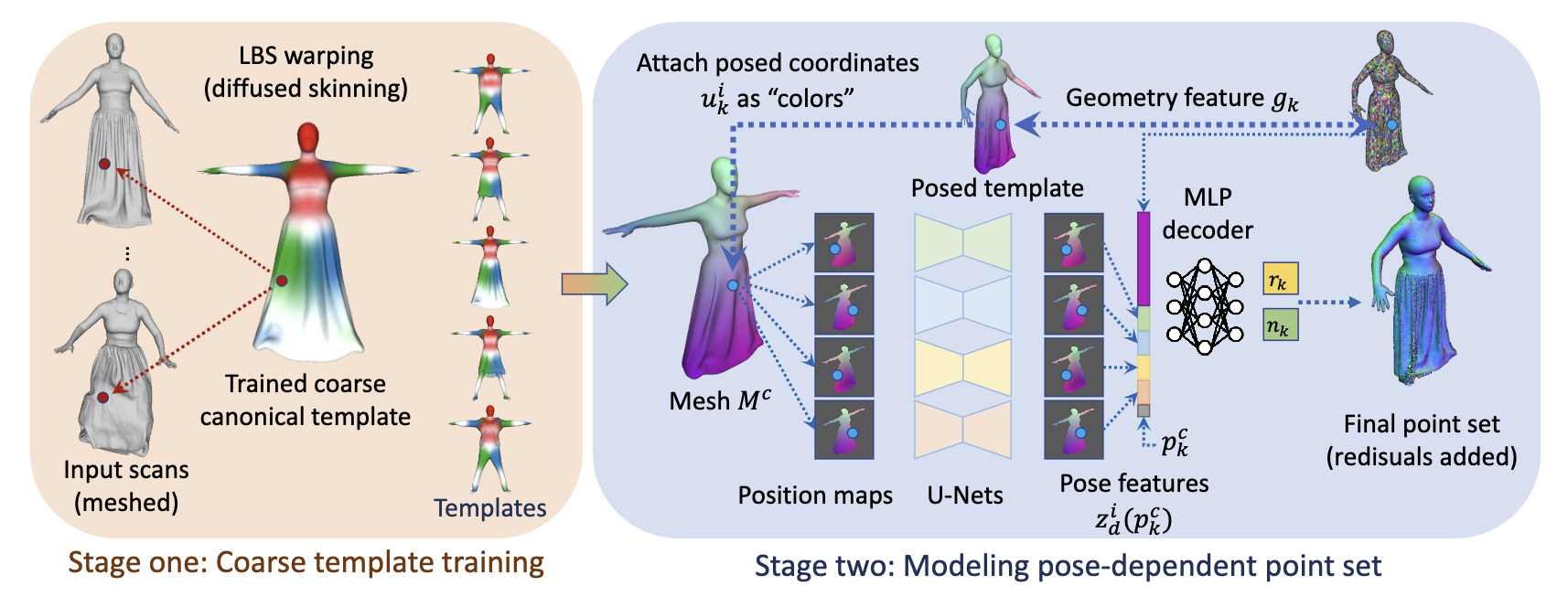
我们提出了一种先隐后显的穿衣人体建模框架,该框架融合了隐式和显式表示法的优点,与现有方法相比,具有更好的拓扑特性。 针对粗模板训练,我们提出了扩散蒙皮策略,即使在数据有限或服装宽松的情况下,也能预测出从标准空间到 pose 空间的稳定对应关系。 为了提取姿态信息,我们提出了基于投影的姿态编码,在没有预定义的 UV 贴图或连接性的前提下,可以通过训练后的模板学习出一个连续的特征空间。 Method Fig. 2: Pipeline 本文的任务是从一组不同服装、不同 pose 的输入中学习出逼真的可动画的穿衣数字人模型。图 2 是本文的 pipeline,第一阶段学习隐式模板,第二阶段预测依赖 pose 的位移。为了简化符号,先假设同一个人只穿一件衣服,后续会说明如何扩展到多件衣服。
本文假设输入是包含法线信息的点集形式,并且衣服覆盖了大部分的身体,因此可以从中提取出 GT 即占用场 (0 表示在外部,1 表示在内部)。对于第 i 帧输入的点集表示为 { p k i } k = 1 N i ⊂ R 3 \{p_k^i\}_{k=1}^{N_i}\subset \R^3 { p k i } k = 1 N i ⊂ R 3 N i N_i N i p k i p_k^i p k i n k i n_k^i n k i
LBS:
q i = W ( p , w ( p ) , T , θ i ) = ∑ j = 1 24 w j ( p ) R j i ( p ) (1) q^i=W(p,w(p),T,\theta^i)=\sum_{j=1}^{24}w_j(p)R^i_j(p) \tag{1} q i = W ( p , w ( p ) , T , θ i ) = j = 1 ∑ 24 w j ( p ) R j i ( p ) ( 1 )
p p p q i q^i q i T T T θ i \theta^i θ i w ( p ) = ( w 1 ( p ) , … , w 24 ( p ) ) ∈ R 24 w(p)=(w_1(p),\dots,w_{24}(p))\in\R^{24} w ( p ) = ( w 1 ( p ) , … , w 24 ( p )) ∈ R 24 p p p R j i ( p ) R_j^i(p) R j i ( p ) T T T θ i \theta^i θ i Stage One: Coarse Template Training with Diffused Skinning 本文用 0-1 占用场的 1/2 等值面 (1/2-level-set) 来表示服装的拓扑——也就是粗模板:
T c = { p ∈ R 3 : F c ( p ) = 1 / 2 } (2) T^c=\{p\in\R^3:F^c(p)=1/2\} \tag{2} T c = { p ∈ R 3 : F c ( p ) = 1/2 } ( 2 )
T c T^c T c F c ( ⋅ ) : R 3 → [ 0 , 1 ] F^c(\cdot):\R^3\rarr[0,1] F c ( ⋅ ) : R 3 → [ 0 , 1 ] 作者认为一个好的前向蒙皮权重场 w σ w ( ⋅ ) : R 3 → R 24 w_{\sigma_w}(\cdot):\R^3\rarr\R^{24} w σ w ( ⋅ ) : R 3 → R 24 σ w \sigma_w σ w
对于 SMPL 表面 T T T p p p w ( p ) w(p) w ( p ) w s ( p ) w^s(p) w s ( p ) w w w n s ( p ) n^s(p) n s ( p ) 这两个特点可以用以下公式来约束:
w ( p ) = w s ( p ) , ∇ p w ( p ) ⋅ n s ( p ) = 0 , f o r p ∈ T (3) w(p)=w^s(p),\ \nabla_pw(p)\cdot n^s(p)=0,\ \ \mathrm{for} \ p\in T \tag{3} w ( p ) = w s ( p ) , ∇ p w ( p ) ⋅ n s ( p ) = 0 , for p ∈ T ( 3 )
因为蒙皮权重场 w w w n s ( p ) n^s(p) n s ( p ) w w w ∇ p w \nabla_pw ∇ p w T T T T T T w = w s w=w^s w = w s
w ( p ) = w s ( p ) , ∇ p w ( p ) = ∇ T w s ( p ) , f o r p ∈ T (4) w(p)=w^s(p),\ \nabla_pw(p)=\nabla_Tw^s(p),\ \ \mathrm{for} \ p\in T \tag{4} w ( p ) = w s ( p ) , ∇ p w ( p ) = ∇ T w s ( p ) , for p ∈ T ( 4 )
可以重新表述为最小化以下能量:
λ p s ∫ p ∈ T ∣ ∣ w ( p ) − w s ( p ) ∣ ∣ 2 + λ g s ∫ p ∈ T ∣ ∣ ∇ p w ( p ) − ∇ T w s ( p ) ∣ ∣ 2 + λ r e g s ∫ R 3 ∣ ∣ ∇ 2 w ∣ ∣ 2 (5) \lambda_p^s\int_{p\in T}||w(p)-w^s(p)||^2+\lambda_g^s\int_{p\in T}||\nabla_pw(p)-\nabla_Tw^s(p)||^2+\lambda_{reg}^s\int_{\R^3}||\nabla^2w||^2 \tag{5} λ p s ∫ p ∈ T ∣∣ w ( p ) − w s ( p ) ∣ ∣ 2 + λ g s ∫ p ∈ T ∣∣ ∇ p w ( p ) − ∇ T w s ( p ) ∣ ∣ 2 + λ re g s ∫ R 3 ∣∣ ∇ 2 w ∣ ∣ 2 ( 5 )
∣ ∣ ∇ 2 w ∣ ∣ 2 ||\nabla^2w||^2 ∣∣ ∇ 2 w ∣ ∣ 2 本文采用 PoissonRecon 来获取 w w w w w w [ 0 , 1 ] [0,1] [ 0 , 1 ]
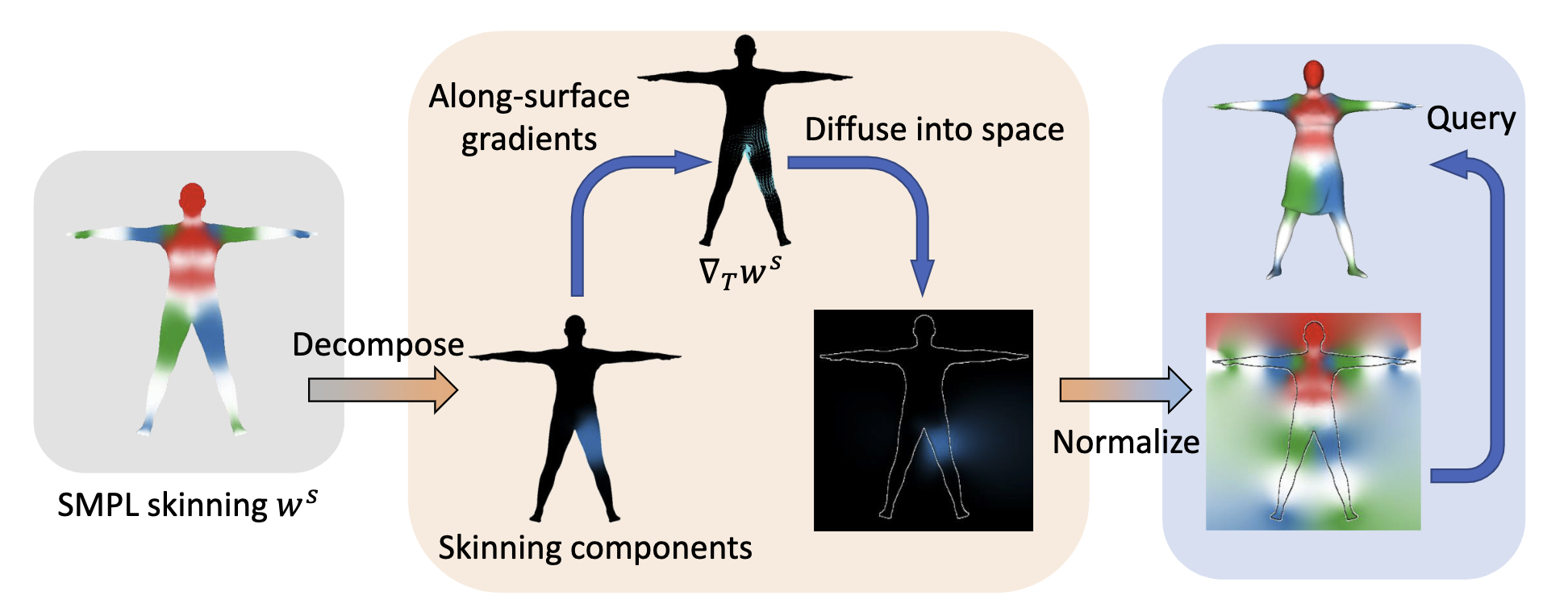
Fig. 3: Diffused skinning visualized. Each component of the skinning weights on SMPL is diffused independently and re-normalized to form a skinning field. 通过公式 5 的到 w w w f σ f ( ⋅ , θ i ) : R 3 → [ 0 , 1 ] f_{\sigma_f}(\cdot,\theta^i):\R^3\to[0,1] f σ f ( ⋅ , θ i ) : R 3 → [ 0 , 1 ] F c F^c F c
F c ( p ) = F σ f ( p , θ i 0 ) , w h e r e θ i 0 = arg min { ∣ ∣ θ i ∣ ∣ 1 : θ i i n t h e t r a i n i n g p o s e s } (6) F^c(p)=F_{\sigma_f}(p,\theta^{i_0}),\ \mathrm{where}\ \theta^{i_0}=\arg\min\{||\theta^i||_1:\theta^i\ \mathrm{in \ the\ training\ poses}\} \tag{6} F c ( p ) = F σ f ( p , θ i 0 ) , where θ i 0 = arg min { ∣∣ θ i ∣ ∣ 1 : θ i in the training poses } ( 6 )
公式 6 其实就是从所有训练 pose 中挑选出 L 1 L_1 L 1 F c ( p ) F^c(p) F c ( p ) T c T^c T c
在得到标准空间的模板后,就可以通过 LBS 转换到 pose 空间:
q k = W ( p k c + c k , w ( p k c ) , T , θ ) + r k (7) q_k=W(p_k^c+c_k,w(p_k^c),T,\theta)+r_k \tag{7} q k = W ( p k c + c k , w ( p k c ) , T , θ ) + r k ( 7 )
p k c p_k^c p k c T c T^c T c { p k c } k = 1 N c \{p_k^c\}_{k=1}^{N_c} { p k c } k = 1 N c q k q_k q k p k c p_k^c p k c c k c_k c k r k r_k r k Pose-Agnostic Template Correction :由于 T c T^c T c c k c_k c k g k g_k g k C ( ⋅ ) C(\cdot) C ( ⋅ )
Projection-Based Pose Encoding :本文用图片来表示编码后的 pose 相关的特征,即 position maps。首先从模版表面提取 mesh,把 pose 空间点的坐标值加标准空间点的坐标值当作颜色,用正交投影的方式渲染成 position maps。和 Animatable Gaussians 获取 position maps 的过程类似,这里借用 Animatable Gaussians 中的图 (图 4) 来展示,只不过 Animatable Gaussians 是只用 pose 空间点的坐标值当作颜色。
Fig. 4: Position Maps in Animatable Gaussians 本文选取左前、左后、右前和右后四个角度,并且四个角度分别有略微覆盖头顶和脚底。最后用 U-Net encoders U d U_d U d
z d i = U d ( I d i ) ∈ R H × W × C p o s e (8) z_d^i=U_d(I_d^i)\in\R^{H\times W\times C_{pose}} \tag{8} z d i = U d ( I d i ) ∈ R H × W × C p ose ( 8 )
I d i ∈ R H × W × 3 I_d^i\in\R^{H\times W\times 3} I d i ∈ R H × W × 3 C p o s e C_{pose} C p ose d = 1 , 2 , 3 , 4 d=1,2,3,4 d = 1 , 2 , 3 , 4 Decoding Pose-Dependent Deformations :最后通过一个 8 层的 MLP D ( ⋅ ) D(\cdot) D ( ⋅ ) r k r_k r k n k n_k n k
[ r k c , n k c ] = D ( [ z i ( p k c ) , g k ] ) , r k c , n k c ∈ R 3 (9) [r_k^c,n_k^c]=D([z^i(p_k^c),g_k]),\ \ \ r_k^c,n_k^c\in\R^3 \tag{9} [ r k c , n k c ] = D ([ z i ( p k c ) , g k ]) , r k c , n k c ∈ R 3 ( 9 )
z i ( p ) = [ z 1 i ( p ) , z 2 i ( p ) , z 3 i ( p ) , z 4 i ( p ) ] z^i(p)=[z_1^i(p),z_2^i(p),z_3^i(p),z_4^i(p)] z i ( p ) = [ z 1 i ( p ) , z 2 i ( p ) , z 3 i ( p ) , z 4 i ( p )] g k g_k g k 当输入数据中有多套服装时,不同服装的模板在第一阶段分别训练,但共享 template corrector C C C U d U_d U d D D D
Training Losses 先跳过。
Reference [1]Learning Implicit Templates for Point-Based Clothed Human Modelingopen in new window