NeRF-论文翻译
NeRF:基于神经辐射场的视图合成
摘要:我们提出了一个方法,通过使用稀疏的输入视图集来优化底层的连续体积场景函数,在复杂场景的新视图合成方面取得了最先进的成果。我们的算法通过一个全连接的深度网络 (非卷积的) 来表示场景,这个网络的输入是一个连续的 5D 坐标 (空间位置 (x, y, z) 和视角 ),输出是该空间位置的体积密度和与视角相关的发射辐射强度。我们通过沿着相机光线采样 5D 坐标来合成新的视图,并且使用经典的体积渲染技术将输出的颜色和密度投射到图片上。因为体渲染有天然的可微分性,因此我们对表示的优化只需要唯一的输入,就是一组知道相机姿势的图像集。我们描述了如何高效的优化神经辐射场来渲染逼真的拥有复杂几何和外观的场景新视图,并且展示在神经渲染和视图生成方面超越前人的结果。查看视图合成的结果的最好方式是视频,因此我们建议读者观看我们的补充视频,以进行有说服性的比较。
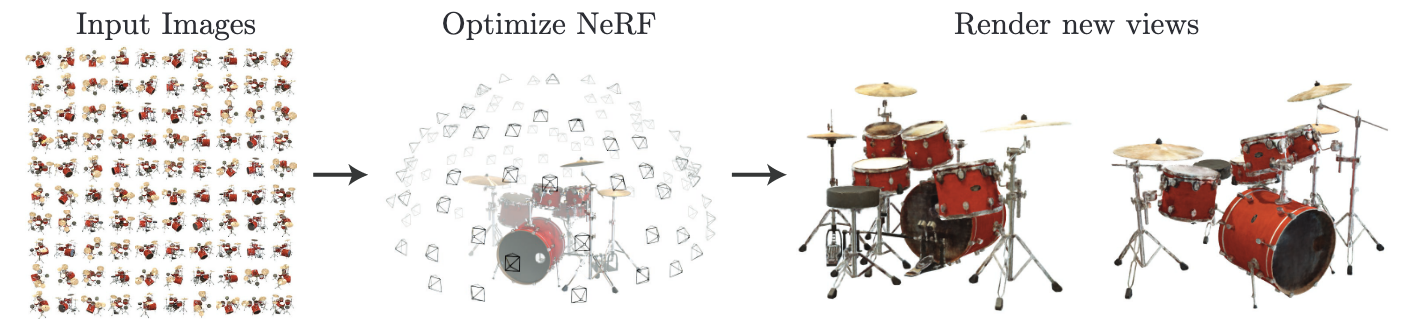
Fig. 1:我们提出了一种方法,可从一组输入图像中优化场景的连续 5D 神经辐射场表示 (任意连续位置的体积密度和视角相关的颜色)。我们使用体渲染的技术,沿着光线累积这个场景表示的样本,从各个视角渲染场景。在这里,我们将在周围半球上随机捕捉到的 100 个合成架子鼓场景的输入视图集合可视化,并且展示了 2 个从我们的优化 NeRF 表示渲染出的新视图。
1 介绍
在此工作中,我们以一个全新的方式解决了一个在视图合成中长期存在的问题,即直接优化一个连续的 5D 场景表示的参数来最小化渲染一组图像的误差。
我们将静态场景表示为一个连续 5D 函数,输出空间中每个点 (x, y, z) 在每个方向 上发出的辐射强度,还有每个点的密度,它就像微分不透明度,控制通过点 (x, y, z) 的光线所累积的辐射。我们的方法优化了一个不包含任何卷机层 (通常也被称为是多层感知机或 MLP) 的全连接深度神经网络来表示这个函数,从单一的 5D 坐标 回归到单一的体积密度和与视角相关的 RGB 颜色。为了从一个特定视角渲染这个神经辐射场 (NeRF),我们:1) 使相机光线穿过场景产生一个 3D 点的采样集,2) 用那些点还有其对应的 2D 视角作为神经网络的输入产生颜色和密度的输出集,3) 并且使用传统的体渲染技术将那些颜色和密度累积成 2D 图像。因为这个过程是自然可微的,我们可以使用梯度下降的方式最小化观测到的图像和我们的方法所渲染的对应视图之间的误差,来优化这个模型。在多个视图最小化这个误差,可以促进网络去预测一个连贯场景的模型,为包含正确底层场景内容的位置分配高体积密度和的精确颜色。图 2 可视化来这一整个流程。

Fig. 2:神经辐射场场景表示和可微渲染过程的概览。我们沿着相机光线采样 5D 坐标 (位置和视角) (a),将那些位置信息放入 MLP 中产生颜色和体积密度 (b),使用体渲染技术将那些数值渲染成图片 (c),这个渲染方程是可微的,因此我们可以通过最小化合成图像和真实观测图像之间的残差来优化我们的场景表示 (d)。
我们发现基础的优化神经辐射场表示一个复杂场景的方法,分辨率不高并且当每条摄像机光线需要大量采样时是低效的。为了解决这些问题,我们通过位置编码对 5D 坐标进行转换使 MLP 能够表示更高频率的函数,并且我们提出分层采用的策略,来减少充分采样高频场景所需的采样次数。
我们的方法继承了体积表示的优点:两者都可以表示复杂现实世界的几何和外观,并且非常适合使用投影图像进行基于梯度的优化。重要的是我们的方法解决了在高分辨率复杂场景建模时,令人望而却步的离散体素的存储成本问题。概括来说,我们的技术有以下几点贡献:
- 一个将复杂几何和材料的连续场景表示为 5D 神经辐射场且参数化为基础的 MLP 网络的方法。
- 一个基于经典体渲染技术的可微分的渲染过程,我们使用这个过程去优化这些标准 RGB 图像的表示。这包括一个分层采样策略,将 MLP 的容量分配给有可见场景内容的空间。
- 通过位置编码将每个 5D 坐标映射到更高维度空间,这样我们可以优化神经辐射场来表示高频场景内容。
我们证明了神经辐射场的方法在数量上和质量上都优于最先进的视图合成方法,包括将神经 3D 表示拟合到场景中还有训练深度卷积网络来预测体积采样表示方面的工作。据我们所知,这篇文章介绍了首个连续神经场景表示,它能够从自然环境中拍摄的 RGB 图像中渲染真实物体和场景的高分辨率逼真新视图。
2 相关工作
最近在 CV 中一个有前途的方向就是使用 MLP 的权重对目标和场景进行编码,MLP 可以直接将 3D 空间位置映射成图形的隐式表示,比如在那个位置的符号距离。但是这些方法迄今为止还不能像使用离散表示法表示场景的技术 (比如三角网格或者体素) 那样,真实地再现拥有复杂几何的现实场景。在这部分,我们回顾了这两项工作并与我们的方法进行对比,我们的方法提高了神经场景表示的能力,因而在渲染复杂现实场景方面取得了最先进的成果。
有一个类似的方法使用 MLP 将低维坐标映射到颜色,也已经被用来表示其他图形学函数,比如图像,纹理材料还有间接照明值。
神经 3D 图形表示 最近的工作研究了连续 3D 图形作为水平集的隐式表示,是通过优化将 xyz 坐标映射到符号距离函数或占用域的深度网络来实现。但是,这些模型受到了限制,因为它们需要获取 3D 几何的真实值 (ground truth),这些真实值通常是从合成三维形状数据集 (如 ShapeNet) 中获取的。后续的工作通过可微渲染方程,只使用 2D 图像来优化神经隐式形状表示,以此降低了对 3D 形状的真实值 (ground truth) 的需求。Niemeyer 等人将曲面表示为 3D 占用域,并使用数值方法找到每条光线的曲面交点,然后使用隐式积分计算一个精确的导数。每条光线的交点位置作为神经 3D 纹理场的输入来预测该点的漫反射颜色。Sitzmann 等人使用一个不太直接的神经 3D 表示,简单地在每个连续 3D 坐标处输出一个特征向量和 RGB 颜色,并提出了一个可微渲染函数,该函数由沿着每条光线前进的循环神经网络组成,以确定曲面的位置。
尽管这些技术在表示复杂和高分辨率的几何方面很有潜力,但是迄今为止还是仅限于低几何复杂性的简单形状,导致渲染出的结果是过于平滑。我们的研究表明,编码 5D 辐射场 (3D 体积和与视角相关的 2D 外观) 是一种优化网络的替代方法,该方法可以表示更高分辨率的几何和外观,渲染出逼真的复杂场景的新视图。
视图合成和基于图像的渲染 给定密集采样的视图,可以通过简单的光场采样插值技术重建逼真的新视图。对于稀疏视图采样的新视图合成,计算机视觉和图形学界通过从观测图像中预测传统的几何和外观表示,已经取得了重大进步。其中一类流行的方法是使用基于网格的场景表示,具有漫反射或与视角相关的外观。可微光栅器或路径追踪器可以直接优化网格表示,以此通过梯度下降来重现一组输入图像。但是基于图像重投影的梯度网格的优化通常比较困难,可能是由于局部最小值或损失函数的糟糕条件所导致的。除此之外,这个方法需要在优化前提供一个具有固定拓扑结构的模版网格进行初始化,这对无约束的真实世界的场景来说常常是不可行的。
另一类方法使用体积表示,解决以一组 RGB 图像作为输入来合成高质量逼真视图的任务。体积方法可以真实地表示复杂的形状和材料,很适合基于梯度的优化,并且相比于基于网格的方法,这种方法产生的视觉干扰更少。早期的体积方法使用观测到的图像直接对体素网格进行着色。最近,许多方法使用更大的多场景数据集训练深度网络,从一组输入图像预测采样的体积表示,并且在测试时使用透明合成 (alpha-compositing) 技术或沿着光线的机器学习合成 (learned compositing) 技术渲染新视图。其他的研究针对每个特定的场景优化了卷积神经网络和采样体素网格的组合,这样卷积神经网络就能补偿低分辨率体素网格带来的离散化瑕疵,或允许预测的体素网格根据输入时间或动画控制而变化。尽管这些体积技术在新视图合成方面已经取得了令人印象深刻的成果,但是由于其采样离散,导致了时间和空间复杂度较差,继而从根本上限制了其扩展到更高分辨率图像的能力——渲染高分辨率的图像需要对 3D 空间进行更精细的采样。我们通过在深度全连接神经网络的参数中对连续体积进行编码来规避这个问题,这不仅比之前的体积方法产生了明显更高质量的渲染结果,并且在存储开销上也更小。
3 神经辐射场场景表示
我们将连续场景表示为一个 5D 向量值函数,其输入为 3D 位置 和 2D 视角 ,输出是颜色 和体积密度 。在实践中,我们将方向表示为一个 3D 笛卡尔单位向量 。我们用 MLP 网络 来近似表示这个连续的 5D 场景表示,并且优化它的权重 将每个输入的 5D 坐标映射到对应的体积密度和该方向的颜色。
我们通过限制网络来预测体积密度 ,将其视为仅与位置 有关的函数,同时允许预测 RGB 颜色 ,将其视为与位置和视角有关的函数,从而使表示具有多视角一致性。为了达到这个结果,首先使用拥有 8 个全连接层 (使用 ReLU 激活函数并且每层拥有 256 个通道) 的 MLP 处理输入的 3D 坐标 ,输出 和 256 维的特征向量。这个特征向量再与相机的视角相连接,然后传递给另外一个全连接层 (使用 ReLU 激活函数且拥有 128 个通道),该层输出与视角相关的 RGB 颜色。
图 3 展示了我们的方法是如何利用输入的视角来表示非 Lambertian 效应。图 4 展示了一个不依赖视角训练出来的模型 (只有 作为输入),它在表示镜面反射的时候效果较差。
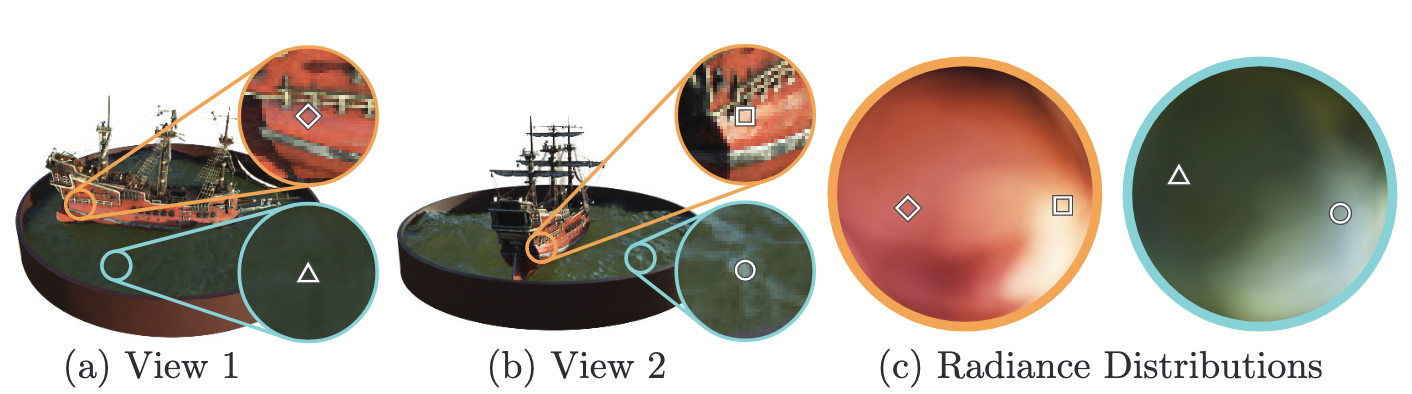
Fig. 3:与视角相关的辐射强度。我们的神经辐射场表示将 RGB 颜色作为空间位置 和视角 的 5D 函数的输出。在这里,我们在轮船场景的神经表示中展示了 2 个位置在不同视角中的颜色。在 (a) 和 (b) 中,我们展示了两个不同相机位置观察到的两个固定的 3D 点的外观:一个在船舷上 (橙色插图),另一个在水面上 (蓝色插图)。我们的方法预测了这两个 3D 点不断变化的镜面外观,并且在 (c) 中我们展示了辐射强度在整个半球的视角上是怎么连续变化的。 (最后一句话不确定是否理解正确)

Fig. 4:我们直观的展示了,与视角相关的辐射强度和通过高频位置编码传递输入坐标是如何提升完整模型的能力。不依赖视角后的模型无法再现推土机踏板上的镜面反射。不使用位置编码会大幅度降低模型表示高频几何和纹理的能力,这会导致过度平滑的外观。
4 利用辐射场进行体渲染
我们的 5D 神经辐射场将场景表示为空间中任意点的体积密度和方向发射辐射强度。我们利用经典的体渲染的原理渲染穿过场景的任意光线的颜色。体积密度 可以解释为射线终止于 处的无限小粒子的微分概率。预期颜色的方程 如下 (其中 是相机光线, 和 分别是近平面和远平面):
方程 表示沿着光线从 到 累积的透射率,也就是光线从 传播到 过程中没有碰撞到其他粒子的概率。从我们的连续神经辐射场中渲染一个新的视图,需要为每一个像素的相机光线求一次 的积分。
我们对这个连续积分进行数值估计,确定性积分法常常用来渲染离散的体素网格。因为 MLP 只能在一组固定的离散位置进行采样,所以这将限制我们表示的分辨率,因此我们使用分层采样法,我们将 分成 N 个均匀的区间,然后从每个区间内均匀随机地采样:
尽管在积分过程中使用了离散样本集,通过分层采样策略,在整个优化过程中 MLP 在连续的位置上进行训练,这有助于连续场景的表示。我们利用这些样本,用 Max 在体渲染中提到过的积分法来对 进行估计:
其中 是相邻采样点之间的距离。这个方程是通过集合 来计算 ,通常是可微的并且可以简化为传统的阿尔法合成,其阿尔法值为 。
5 优化神经辐射场
在上一节中,我们已经描述了将场景建模成神经辐射场并从这个表示中渲染新视图所必需的核心内容。但是,我们发现想要取得最好的质量,这些内容并不足够,这在 6.4 节中有证明。为了表示出高分辨率的复杂场景,我们将介绍两个改进。第一个是输入坐标的位置编码,有助于 MLP 表示高频函数,第二个是分层采样,这使我们能有效地采样这个高频表示。
5.1 位置编码
尽管神经网络是通用函数近似器,我们发现当直接把坐标 输入网络 进行运算时,其渲染的结果在表示颜色和几何的高频变化方面效果较差。这和 Rahaman 等人最近的研究相一致,他们的研究表明深度网络更偏向于学习低频函数。他们还表明想要拟合包含高频变化的数据,可以在将数据输入到网络之前,使用高频函数将其映射到更高维的空间。
我们在神经场景表示的背景下利用这些发现,并且发现将 重新定义为两个函数的组合 (一个已经学习,一个还没有),可以显著提高性能 (见图 4 和表 2)。其中 可以将参数从 映射到更高维空间 , 依然是一个普通的 MLP。我们所使用的编码方程:
这个方程 分别应用于 (归一化到 ) 中的三个坐标还有笛卡尔视角单位向量 (归一化到 ) 的三个分量。在我们的实验中,我们对 设置 ,对 设置 。
一个类似的映射也被应用到 Transformer 模型中,并称其为位置编码。但是,Transformer 使用位置编码却有着不同的目的,其目的在于对位置顺序没有概念的模型,提供输入序列中的标记的离散位置信息。相比之下,我们使用这些函数将连续的输入坐标映射到更高维度的空间,来使 MLP 能够容易地近似一个更高频的函数。同时,从投影中建模 3D 蛋白质结构的相关问题也使用了类似的输入坐标映射。
5.2 分层体积采样
我们的渲染策略是在每条摄像机光线上的 N 个点上密集评估神经辐射场网络,但这种策略效率不高:对渲染图像没有意义的自由空间和遮挡区域仍然需要重复采样。我们从体渲染的研究中获取灵感,提出了分层表示法,根据最终渲染的预期效果按比例分配采样,提升了渲染效率。
我们同时优化两个网络 (一个粗网络和一个细网络) 而不是只使用一个网络来表示场景,我们首先使用分层采样对 个位置进行采样,然后如公式 2 和 3 所述,评估这些位置的粗网络。在得到这个粗网络的输出后,我们会对每条光线的点进行更有依据的采样,更偏向于采样与体积相关的部分。为此,我们首先将公式 3 中的粗网络中的阿尔法合成颜色 重写为沿光线采样到的所有颜色 的加权和:
将权重归一化为 ,就能得到沿着射线的分段常数概率密度函数 (PDF)。我们使用逆变换采样 (inverse transform sampling) 在该分布中的 个位置进行第二组采样,结合两组采样对细网络进行评估,并且使用所有 个样本结合公式 3 计算最后渲染出的光线颜色 。这一过程将在更多有可见内容的区域进行采样。这达到了一个类似重要性采样的目的,但是我们使用采样的值作为整个积分域的非均匀离散化,而不是将每个样本视为对整个积分的独立概率估计。
5.3 实现细节
我们为每个场景优化了一个单独的神经连续体表示网络。这只需要一个场景的 RGB 图片的数据集,对应的相机姿态和内在参数以及场景边界 (对于合成物体的图片就使用真正的相机姿态、内在参数还有边界,对于真实拍摄的图片就使用 COLMAP 来估计这些参数)。在每轮优化迭代中,我们从数据集中的所有像素集中随机采样一个 batch 的相机光线,然后根据 5.2 节中提到的分层采样技术,从粗网络中采样 个样本,从细网络中采样 个样本。使用第 4 节中提到的体渲染技术根据两组样本渲染每条光线的颜色。我们的损失函数是简单地计算渲染出的像素颜色和真实颜色之间的平方差 (分别计算出粗渲染和细渲染,再求两者之和):
其中 是每个 batch 中的光线的集合,, 和 分别是光线 的真实的 RGB 颜色,粗网络预测的 RGB 颜色和细网络预测的 RGB 颜色。尽管最后渲染的结果是 ,我们也需要最小化 的损失,因为从粗网络得到的权重分布可以用来分配细网络中的采样点。
在我们的实验中,我们设置 batch 大小为 4096 个光线,在粗网络中采样 个样本,在细网络中额外采样 个样本。我们使用 Adam 优化器,学习率从 开始,在优化过程中指数式下降到 (其他 Adam 的超参数保持默认值 )。单一场景的优化在一个 NVIDIA V100 GPU 上通常需要 100-300k 次迭代 (大约 1-2 天)。
6 结果
我们的方法在数量上 (见表 1) 和质量上 (见图 8 和 6) 都超过先前的研究,还做了许多消融实验去验证我们的选择 (见表 2)。我们强烈建议读者去看我们的补充视频,以便更好地理解我们的方法与已有的基准方法相比,在渲染新视图的平滑路径方面取得了显著提升。

Table 1:无论在合成图像还是真实图像的数据集上,我们的方法在数量上都优于之前的研究成果。我们记录了 PSNR/SSIM (越高越好) 和 LPIPS(越低越好)。DeepVoxels 数据集由 4 个简单几何的漫反射物体组成。我们的仿真数据集包含 8 个 几何形状复杂的物体的路径追踪渲染图,这些物体具有复杂的非 Lambertian 材料。真实数据集包含 8 个真实世界场景的手持式面向前方拍摄的图像 (由于 NV 只能重建有界体积内的物体,因此无法在此数据集上进行评估)。尽管 LLFF 在 LPIPS 上表现地稍微好一点,我们强烈建议读者去观看补充视频,与已有的基准方法相比,我们的方法在多视图一致性上表现的更好,且产生的瑕疵更少。
6.1 数据集
渲染合成的物体 我们首先展示了两个渲染合成的物体的数据集的实验结果 (表 1 "Diffuse Synthetic 360°" 和 "Realistic Synthetic 360°")。DeepVoxels 数据集包含四个有着简单几何的 Lambertian 物体。每个物体根据上半球体采样的视点渲染在 的像素图上 (479 个作为输入,1000 个作为测试)。我们还额外生成了自己的数据集,包含路径追踪渲染的八个物体,具有复杂的几何和真实的非 Lambertian 的材料,其中六个是根据上半球体采样的视点渲染出来的,剩下两个是根据整个球体采样的视点渲染出来的。我们为每个场景渲染了 100 个视图作为输入,200 个用于测试,且都是 像素的。
复杂场景的真实图像 我们展示了粗略地面向前方拍摄的复杂真实世界场景的结果 (表 1 "Real Forward-Facing")。这个数据集包含 8 个由手持手机拍摄的场景 (其中 5 个是 LLFF 论文中的,剩下 3 个是我们拍摄的),拍摄了 20 到 62 张图片,取出其中的 1/8 作为测试集。所有的图像是 像素大小。
6.2 比较
为了评估我们的模型,我们对比了当前在视图合成方面表现出色的技术,细节如下。除了 LLFF 外,其他的所有方法都使用相同的输入视图数据集为每个场景训练一个单独的网络。对于 LLFF,在一个更大的数据集上训练一个单独的 3D 卷积网络,然后在测试的时候使用相同的训练网络处理新场景的输入图像。
Neural Volumes (NV) 合成物体的新视图,该物体完全位于一个有边界的体积内,且在独特的背景前 (这个背景必须单独拍摄且不含物体)。它优化了一个深度 3D 卷积网络来预测包含 个样本的离散化 体素网格和包含 个样本的 3D 变形网格。该算法通过让相机光线穿过变形体素网格来渲染新视图。
Scene Representation Networks (SRN) 将一个连续场景表示为不透明的表面,由 MLP 隐式定义,该 MLP 将每个 坐标映射到一个特征向量。他们利用任意 3D 坐标处的特征向量来预测光线的下一步步长,从而训练循环神经网络沿光线在场景中前进。最后一步的特征向量解码成曲面上的单一颜色。注意,SRN 是 DeepVoxels 的同一作者的后续性能更好的算法,这也是为什么我们不和 DeepVoxels 做比较。
Local Light Field Fusion (LLFF) LLFF 设计用于为采样良好的面向前方拍摄的场景生成逼真的新视图。使用训练好的 3D 卷积网络直接预测输入视图的离散的视锥体采样 网格,通过阿尔法合成和将附近的 MPIs 混合到新的视点中来渲染新的视图。

Fig. 5:使用基于物理的渲染器生成的场景视图的测试集比较。我们的方法在几何和外观上都能复原出良好的细节,比如船舶的绳索,乐高的齿轮和踏板,麦克风闪亮的支架和金属网格,还有 Materials 上非 Lambertian 反射。LLFF 在麦克风支架上出现了条纹,Materials 的边缘处理不准确,船的桅杆和乐高内部出现鬼影。 SRN 在每个案例中的渲染都模糊不清。NV 捕捉不到麦克风金属网格或乐高齿轮的细节,且完全没法复原船舶的绳索的几何。

Fig. 6:真实世界场景视图的测试集比较。LLFF 是专门为了这类案例 (面向前方拍摄的真实场景) 而设计的。我们的方法相比于 LLFF, 能够在渲染视图中表示出更精细的几何。就像上图蕨类植物 (Fern) 的叶子,霸王龙的肋骨和图中的栏杆所示,我们的方法还能正确重建被部分遮挡的区域,这也是 LLFF 难以清晰呈现的部分,比如底部蕨类植物叶子后面的黄色架子,还有兰花底部的背景中的绿叶。多个渲染之间的混合也会导致 LLFF 出现重复边缘,就像兰花顶部所示那样。SRN 可捕捉每个场景中的低频几何图形和色彩变化,但无法复原任何精细细节。
6.3 讨论
在所有场景中,我们的表现都远优于其他两个为每个场景优化独立网络的基准方法 (NV 和 SRN)。此外,与 LLFF 相比,我们只使用它们的输入图像作为整个训练集,就能生成质量和数量上都优于 LLFF 的渲染效果 (除一项指标外的所有指标)。
SRN 方法会产生过于平滑的几何和纹理,而且由于每条摄像机光线只能选择单一的深度和颜色,因此它在视图合成方面的表现力受到限制。NV 能够捕捉还过得去的体积几何和外观,但其底层使用的显式 象素网格使其无法在高分辨率下表现精细的细节。LLFF 特别规定了 "采样准则",即输入视图之间的差距不得超过 64 像素,因此在视图之间差距高达 400-500 像素的合成数据集中,LLFF 经常无法估算出正确的几何。此外,LLFF 在渲染不同视图时会融合不同的场景表示,从而导致感知上的不一致性,这在我们的补充视频中显而易见。
这些方法之间最大的实际权衡是时间与空间。所有比较的单个场景都需要至少 12 个小时的训练。相比之下,LLFF 可在 10 分钟内处理一个小型输入数据集。但是,LLFF 会为每个输入图像生成一个大型 3D 体素网格,从而导致巨大的存储开销 (一个 "仿真" 场景的存储容量超过 15GB)。我们的方法只需要 5MB 来存储网络中的权重 (与 LLFF相比,压缩了 3000 倍),这甚至比我们任何一个数据集中的单个场景的输入图像本身所需的内存还要小。
6.4 消融实验
表 2 的大量消融实验验证了我们算法的设计和参数选择,是我们在 "Realistic Synthetic 360°" 场景上进行实验的结果。第 9 行展示了完整模型作为参考。第 1 行是我们模型的极简版本,没有位置编码 (PE),没有视角依赖 (VD),没有分层采样 (H)。第 2-4 行我们从完整模型中逐一移除这三个组成部分,观察到位置编码 (第 2 行) 和视角依赖 (第 3 行) 对模型的帮助最大,其次是分层取样 (第 4 行)。第 5-6 行显示了性能是如何随着输入图像数量的减少而下降的,需要注意的是,当我们的方法只使用 25 张输入图像时,其性能在所有指标上都超过了 NV、SRN 和 LLFF 使用 100 张图片时的性能 (见补充材料)。在第 7-8 行,我们验证了在 的位置编码中已经使用了最大频率 ( 所使用的最大频率按比例缩放),当频率设置为 5 时会降低性能,但将频率从 10 增加到 15 并不会提高性能,我们确信一旦 超过输入图像中的最大频率 (在我们的数据中大约为 1024),增加 就没有什么好处。

Table 2:我们模型的消融实验。各项指标是我们仿真数据集中 8 个场景的平均值。具体细节看 6.4 节。
7 结论
我们的研究直接解决了之前使用 MLP 将物体和场景表示为连续函数的研究的不足之处。我们证明了将场景表示为 5D 神经辐射场 (一个 MLP,可根据 3D 位置和 2D 视角输出体积密度和与视角相关的发射辐射强度) 渲染出的效果比先前主流的训练深度卷积网络输出离散体素表示的方法要更好。
尽管我们已经提出了分层采样策略来使采样更高效 (同时包括训练和测试),在研究有效优化和渲染神经辐射场的技术方面,还有许多工作要做。未来工作的另一个方向是可解释性:体素网格和网格等采样表示法可以解释渲染视图的预期质量和故障模式,但是,当我们将场景编码到深度神经网络的权重中时,如何分析这些问题还不清楚。我们相信,这项工作在基于真实世界图像的图形管道方面取得了进展,复杂的场景可以由根据实际物体和场景图像优化的神经辐射场组成。
感谢 ...
References
....
额外的实现细节
网络结构 图 7 展示了简单全连接网络的结构。
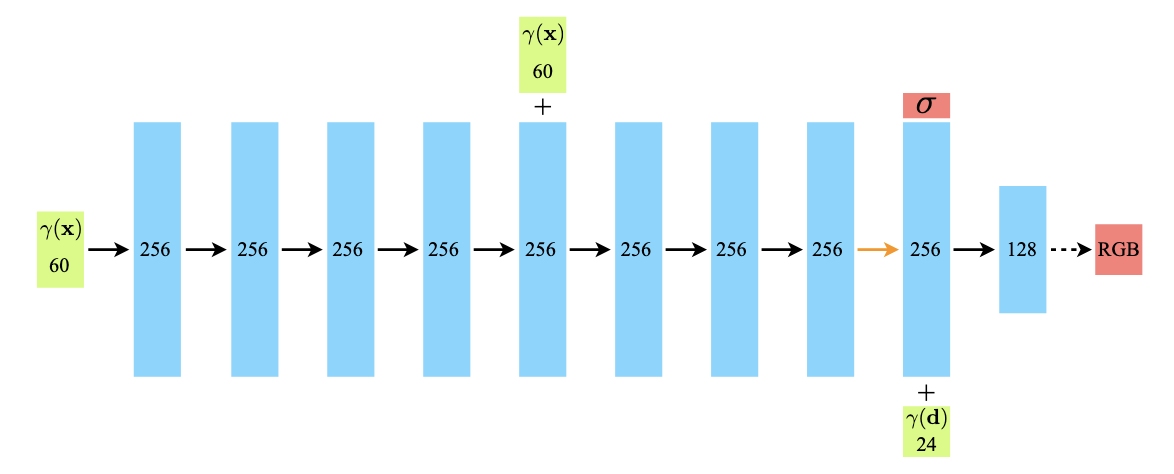
Fig. 7:全连接网络结构图。绿色是输入的向量,蓝色是中间的隐藏层,红色是输出向量,方框中的数字表示向量的维度。每一层都是标准的全连接层,黑色箭头表示该层使用 ReLU 激活函数,橙色箭头表示该层没有激活函数,黑色虚线箭头表示该层使用 Sigmoid 激活函数,"+" 表示向量连接。输入位置 的位置编码通过 8 个全连接 ReLU 层,每层有 256 个通道。我们采用 DeepSDF 架构,并包含一个跳跃连接,并将这一输入连接到第五层。额外一层输出体积密度 (使用 ReLU 激活函数确保输出的体积密度为非负值) 和 256 维的特征向量,这个特征向量与输入视角的位置编码 相连接,并由下一个 128 通道的使用 ReLU 激活函数的全连接层处理。最后一层 (采用 Sigmoid 激活函数) 输出从位置 沿着视角 发射的光线的 RGB 辐射强度。
体积边界 我们的方法通过采样沿摄像机光线的连续 5D 坐标处的神经辐射场表示来渲染视图。在使用合成图像进行实验时,我们会缩放场景,使其位于以原点为中心、边长为 2 的立方体内,并只采样该边界体积内的表示。我们的真实图像数据集包含的内容可能存在于最近点和无穷远之间的任何地方,因此我们使用标准设备坐标系 NDC 将这些点的深度范围映射到 之间。这将所有光线的起点移动到场景的近平面,将相机的透视光映射为变换后体积中的平行光线,并使用视差而不是使用度量深度,因此所有坐标都是有界限的。
训练细节 对于真实场景数据,我们在优化过程中对输出的 添加均值为零、方差为一的随机高斯噪声 (在激活函数 ReLU 之前) 来进行正则化,发现这略微提高了渲染新视图的视觉效果。我们通过 Tensorflow 来实现我们的模型。
渲染细节 为了在测试时渲染新的视图,我们通过粗网络对每条光线采样 个点,通过细网络对每条光线采样 个点,对每条光线共进行 次采样。对于仿真数据集,每张图片需要 640k 条光线,对于真实场景,每张图片需要 762k 条光线,因此每张渲染图像的采样次数在 1.5 亿 到 2 亿次之间,在一张 NVIDIA V100 显卡上,每一帧大约需要花费 30 秒。