NeRF-论文解析
NeRF 是做什么的
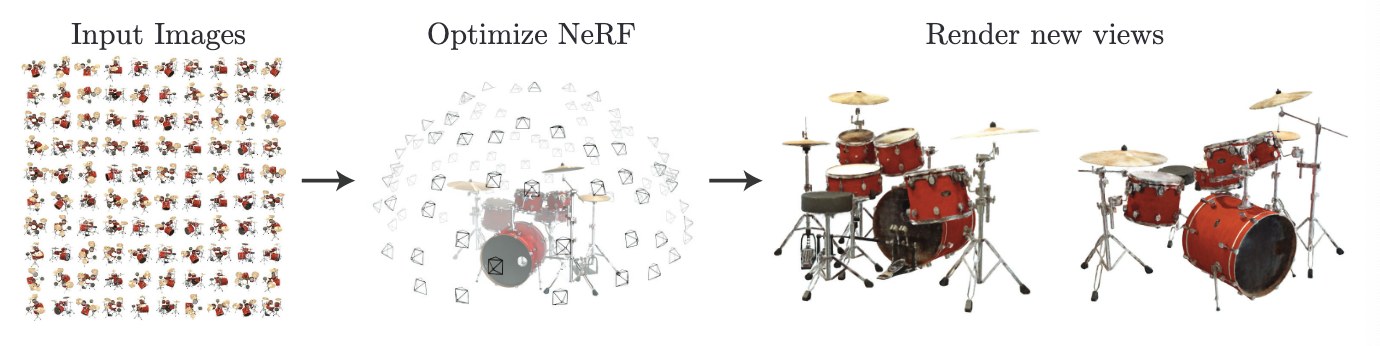
想知道一个模型是干什么的,最简单的方式就是看这个模型的输入输出。先忽略内部细节,NeRF 的输入就是对一个物体从不同角度拍摄的多张图片,输出就是渲染出来的输入集中所没有的新视角下的图片 (如图 1 所展示的那样),简而言之 NeRF 就是合成新视角下的视图的模型。
NeRF 是怎么做的
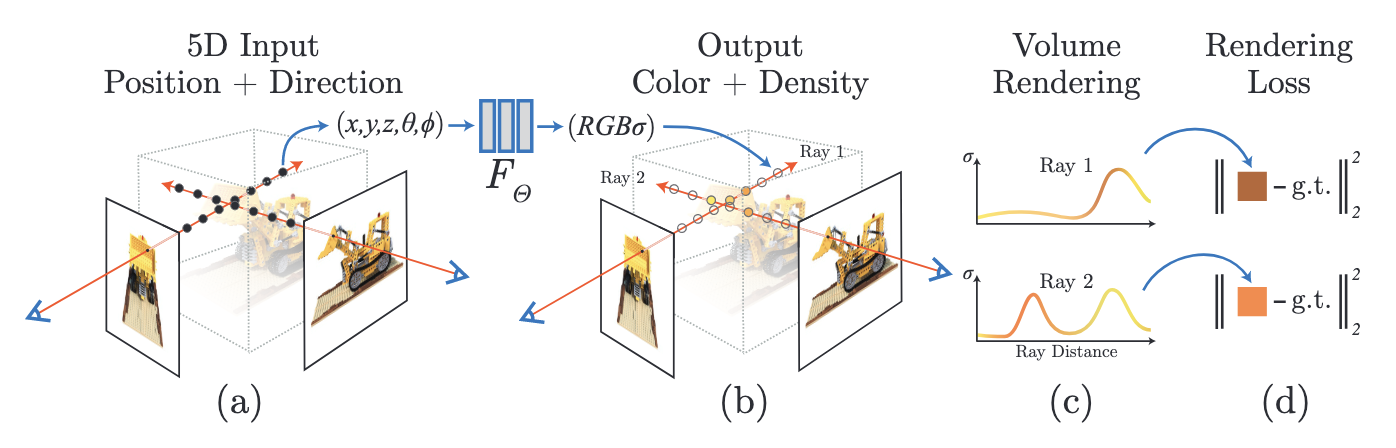
Pipeline
- (a). 沿着每个像素的光线进行采样,将采样点的 3 维空间坐标和 2 维视角输入 MLP。
- (b). 通过 MLP 计算出每个采样点的颜色和密度。
- (c). 通过体渲染技术渲染出每个像素的颜色并合成图像。
- (d). 体渲染的函数是可微的,因此通过损失函数 (损失函数是计算渲染出的像素颜色和真实像素颜色之间的平方差) 来优化模型。
实现细节
采样
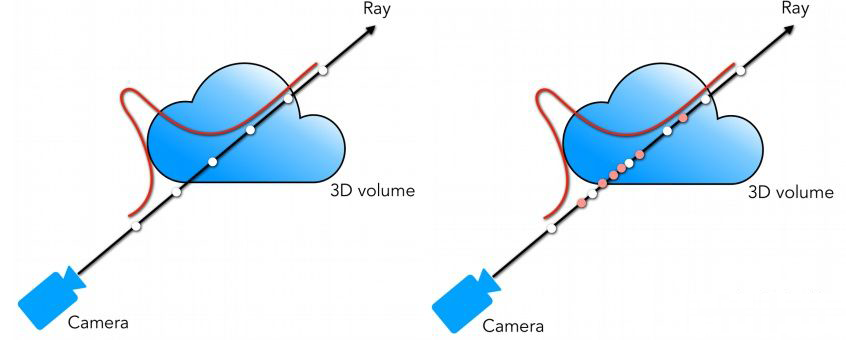
NeRF 在采样中使用了一个 trick,就是分层采样 (Hierarchical Sampling),简单来说就是训练两个网络 ,粗网络 (Coarse) 和细网络 (Fine)。粗网络会沿着光线均匀采样 64 个点,通过粗网络的结果可以知道 Volume 中哪些地方密度更大更值得被采样 (原理在 前置知识 (4.2节) 中有详细解释)。细网络会采样 64 + 128 个点,其中 64 个就是粗网络采样的点,剩下 128 个是基于粗网络的结果,使用逆变换采样 (Inverse Transform Sampling) 的方法在密度大的地方进行采样。
位置编码
NeRF 中的另一个 trick,就是位置编码 (Positional Encoding)。NeRF 的团队在他们的另一篇论文中表明 MLP 更倾向于学习低频信息。解决这个问题的方法就是位置编码,使用傅里叶特征映射 (Fourier Features Mapping):
可以将参数从 映射到更高维的空间 ,NeRF 中对空间坐标 和视角 分别设置 和 ,即将 和 都从 3 维 (在论文中视角 是 2 维的,但是输入模型前会转换成 3 维) 分别映射到 60 维和 24 维。当把输入从低维转换到高维之后,就可以让 MLP 学会高频信息。
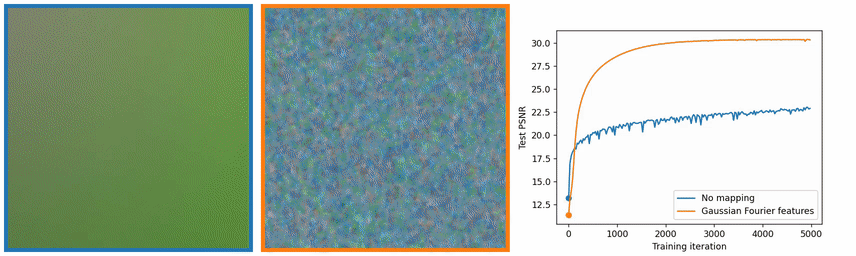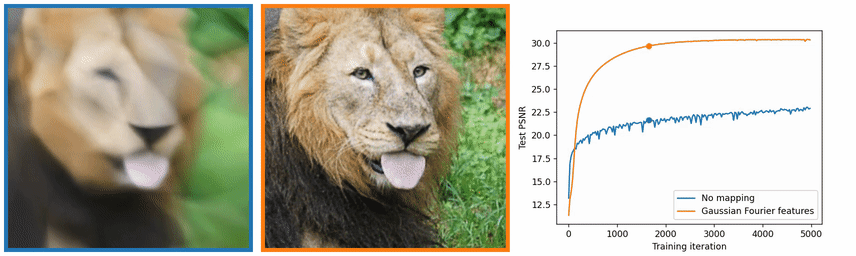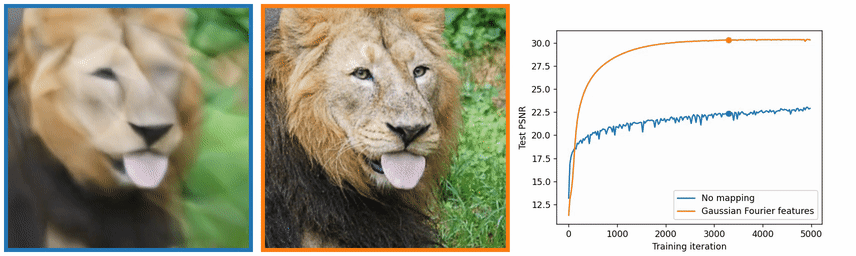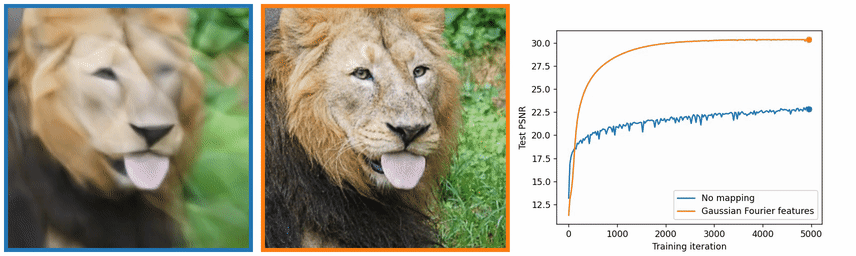
图像中的高频信息是灰度变化比较大的地方,也就是边缘和纹理,图 4 中也可以看出,没有使用位置编码,学习出来的图像在边缘和纹理上效果很差。
模型
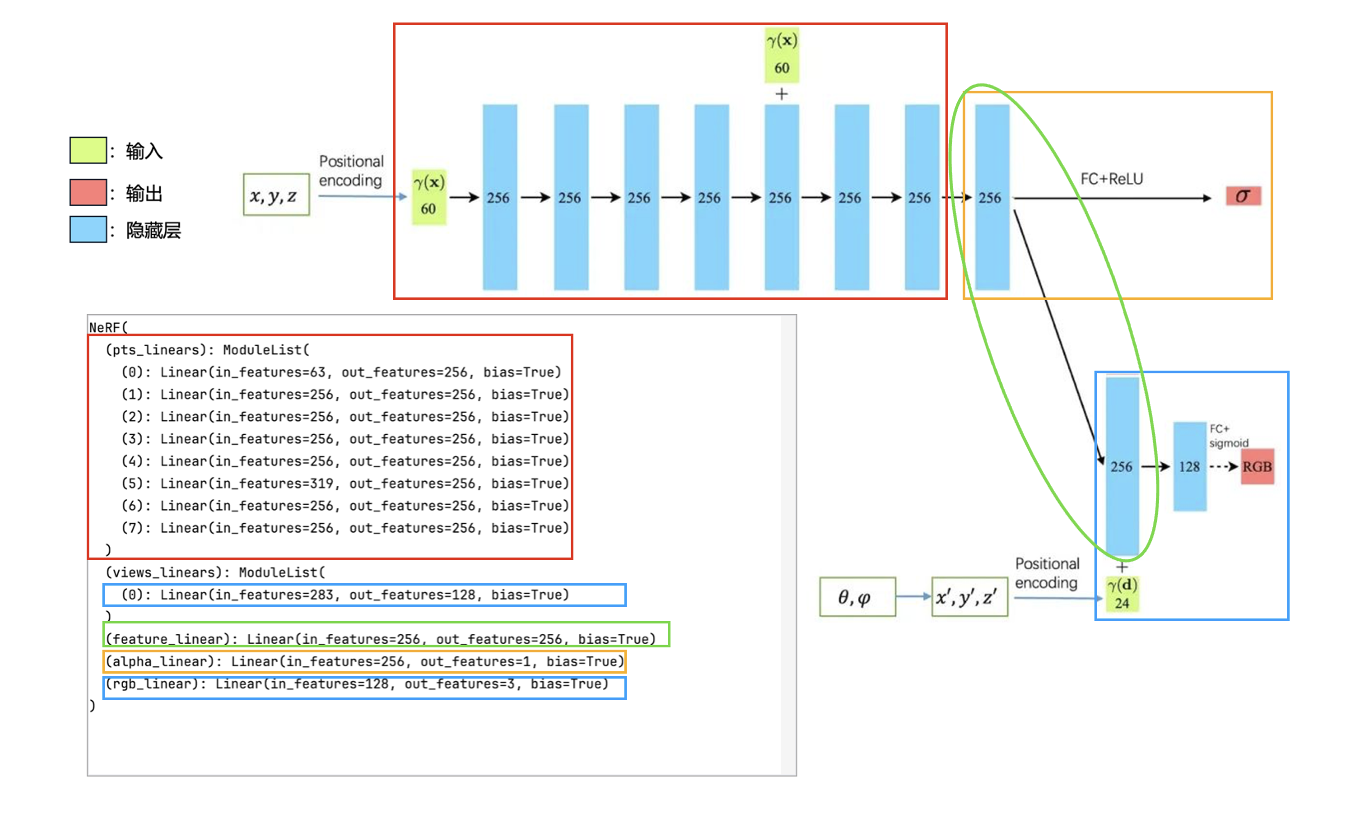
NeRF 的模型架构如图 5 所示,并且具体代码实现用相同颜色的框进行了标注。
体渲染
NeRF 做的怎么样
Reference
[1]Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
[2]NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis