Segment Any 3D Gaussians 项目地址open in new window
arXiv preprint arXiv:2312.00860 (这里看的是 v1 版本)
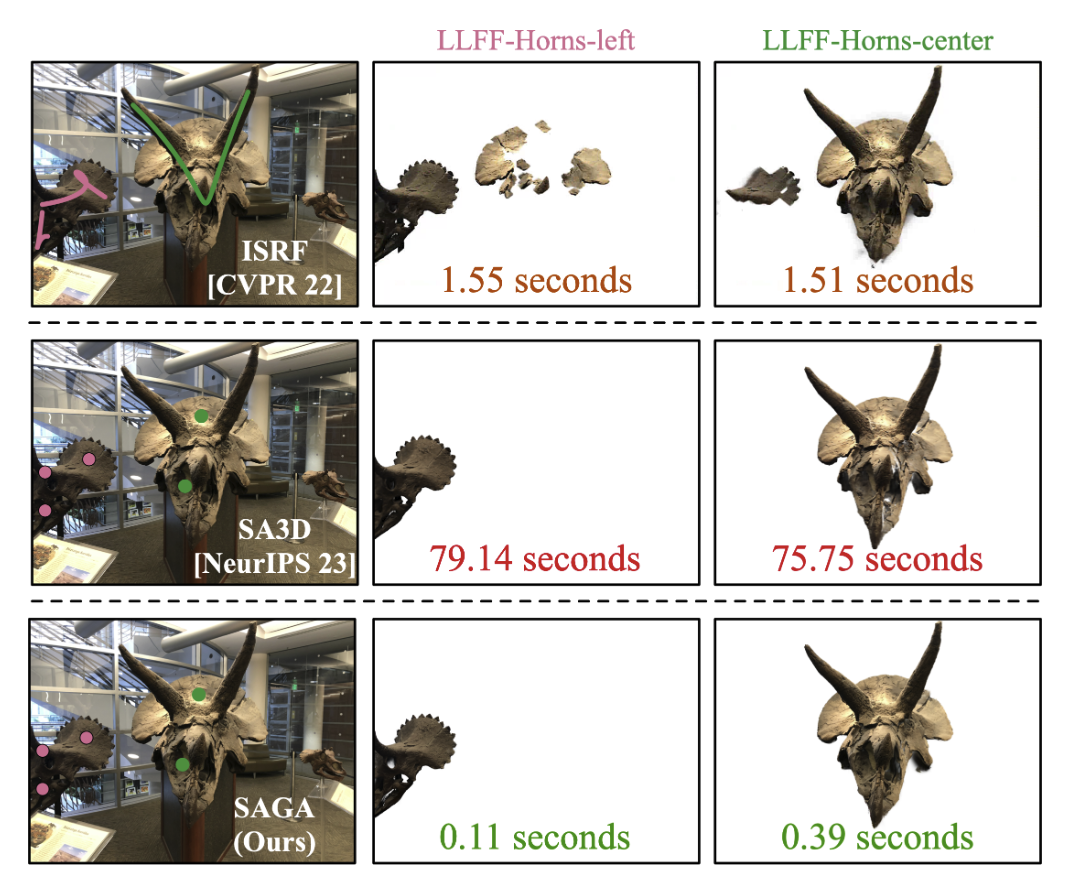
Fig. 1: Overview Abstract 在辐射场中进行交互式 3D 分割是一项很有吸引力的任务,因为它对 3D 场景的理解和操作非常重要。然而,现有的方法在实现细粒度、多粒度分割方面面临着挑战,或者要与巨大的计算开销作斗争,从而阻碍了实时交互。本文介绍了 Segment Any 3D GAussians (SAGA),这是一种新颖的 3D 交互式分割方法,它将 2D 分割基础模型与 3DGS 无缝融合在一起。SAGA 通过精心设计的对比训练,将由分割基础模型生成的多粒度 2D 分割结果有效地嵌入到 3D 高斯点特征中。对现有 benchmarks 的评估表明,SAGA 的性能可与最先进的方法相媲美。此外,SAGA 还能实现多粒度分割,并适应各种提示,包括点、涂鸦和 2D mask。值得注意的是,SAGA 可以在几毫秒内完成 3D 分割,与之前的 SOTA 相比,实现了近 1000 倍的加速。
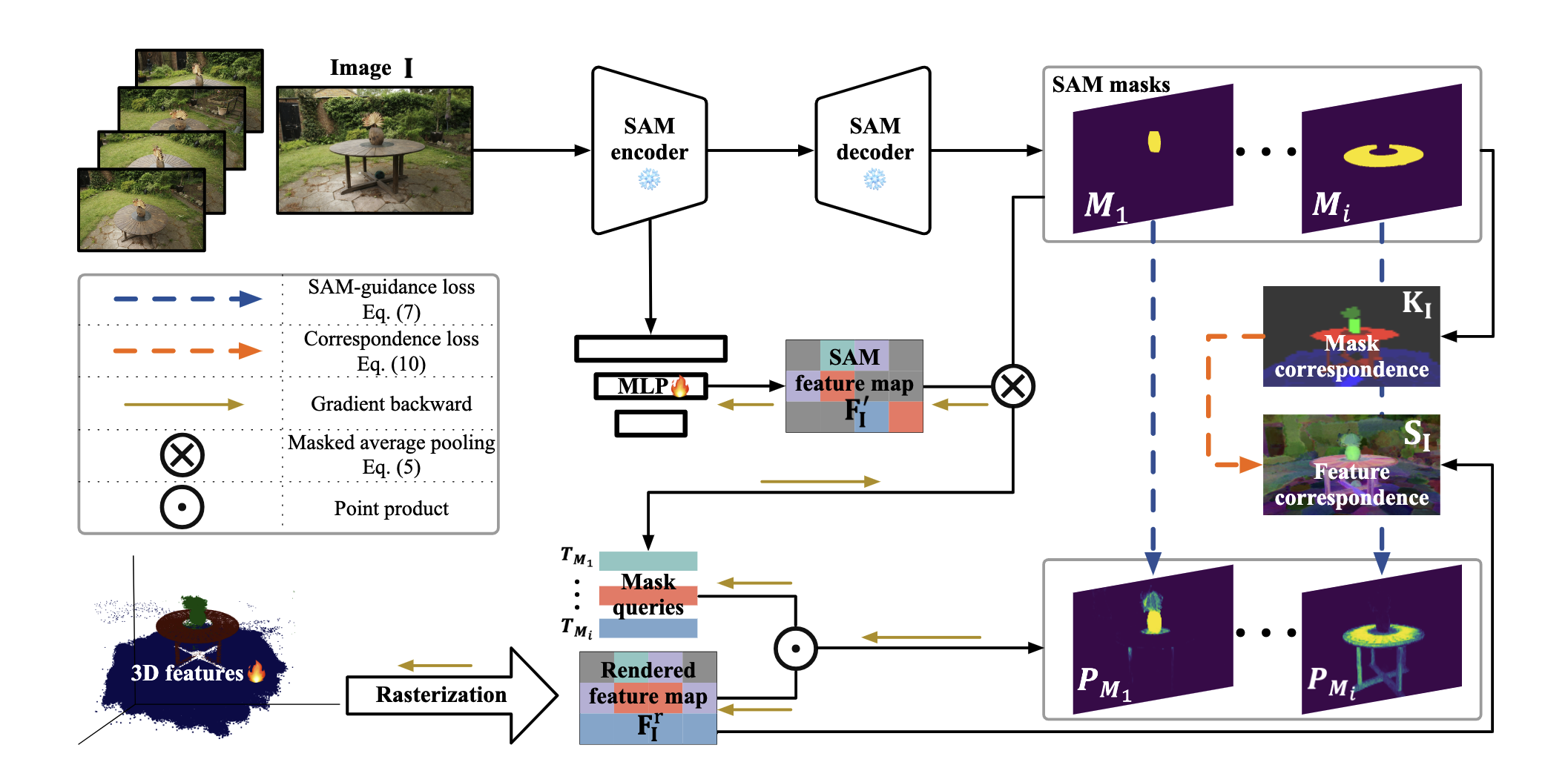
Method Fig. 2: Pipeline Preliminary 3D Gaussian Splatting (3DGS) :这部分直接跳过。
Segment Anything Model (SAM) :输入图片 I \mathbf{I} I P \mathcal{P} P M \mathbf{M} M
M = S A M ( I , P ) (1) \mathbf{M}=\mathrm{SAM}(\mathbf{I},\mathcal{P}) \tag{1} M = SAM ( I , P ) ( 1 )
Overall Pipeline 如图 2 所示,给定一个预训练 3DGS 模型 G \mathcal{G} G I \mathcal{I} I I \mathcal{I} I I ∈ R H × W \mathbf{I}\in\R^{H\times W} I ∈ R H × W F I S A M ∈ R C S A M × H × W \mathbf{F}_{\mathbf{I}}^{\mathrm{SAM}}\in\R^{C^{\mathrm{SAM}}\times H\times W} F I SAM ∈ R C SAM × H × W M I S A M \mathcal{M}^{\mathrm{SAM}}_{\mathbf{I}} M I SAM G \mathcal{G} G g \mathbf{g} g f g ∈ R C \mathbf{f}_{\mathbf{g}}\in\R^{C} f g ∈ R C C C C
在推理的阶段,对于一个特定视角,有相机位姿 v v v P \mathcal{P} P Q \mathcal{Q} Q
Training Features for Gaussians 给定一张带有特定相机位姿 v v v I \mathbf{I} I G \mathcal{G} G p p p F I , p r \mathbf{F}^r_{\mathbf{I},p} F I , p r
F I , p r = ∑ i ∈ N f i α i ∏ j = 1 i − 1 ( 1 − α j ) (2) \mathbf{F}_{\mathbf{I}, p}^r=\sum_{i \in \mathcal{N}} \mathbf{f}_i \alpha_i \prod_{j=1}^{i-1}\left(1-\alpha_j\right) \tag{2} F I , p r = i ∈ N ∑ f i α i j = 1 ∏ i − 1 ( 1 − α j ) ( 2 )
N \mathcal{N} N 在训练阶段,冻结 3D 高斯的其他所有参数。
SAM-guidance Loss :通过 SAM 自动提取的 2D mask 十分复杂且容易混淆 (即三维空间中的一个点在不同视角上可能被分割为不同的物体)。为了解决这个问题,本文提出用 SAM 生成的 features 来 guidance。如图 2 所示,首先用 MLP φ \varphi φ
F I ′ = φ ( F I S A M ) (3) \mathbf{F}_{\mathrm{I}}^{\prime}=\varphi\left(\mathbf{F}_{\mathrm{I}}^{\mathrm{SAM}}\right) \tag{3} F I ′ = φ ( F I SAM ) ( 3 )
然后对于 mask 集合 M I S A M \mathcal{M}^{\mathrm{SAM}}_{\mathbf{I}} M I SAM M \mathbf{M} M T M ∈ R C \mathbf{T}_\mathbf{M}\in\R^C T M ∈ R C
T M = 1 ∥ M ∥ 1 ∑ p = 1 H W 1 ( M p = 1 ) F I , p ′ (4) \mathbf{T}_{\mathbf{M}}=\frac{1}{\|\mathbf{M}\|_1} \sum_{p=1}^{H W} \mathbb{1}\left(\mathbf{M}_p=1\right) \mathbf{F}_{\mathbf{I}, p}^{\prime} \tag{4} T M = ∥ M ∥ 1 1 p = 1 ∑ H W 1 ( M p = 1 ) F I , p ′ ( 4 )
就是求 mask 区域特征的均值作为这个 segmentation 的特征值,是个单位向量。
然后 T M \mathbf{T}_\mathbf{M} T M
P M = σ ( T M ⋅ F I r ) (5) \mathbf{P}_\mathbf{M}=\sigma(\mathbf{T}_\mathbf{M}\cdot\mathbf{F}_\mathbf{I}^r) \tag{5} P M = σ ( T M ⋅ F I r ) ( 5 )
σ \sigma σ 因为特征值是单位向量,所以进行点乘就是求余弦相似度,这里就是在算 rendered feature map 的每个像素和哪个特征值最接近,本质上就是在看这个像素是属于哪个 segmentation。
SAM-guidance loss 被定义为分割结果 P M \mathbf{P}_\mathbf{M} P M M \mathbf{M} M
L S A M = − ∑ I ∈ I ∑ M ∈ M I ∑ p H W [ M p log P M , p + ( 1 − M p ) log ( 1 − P M , p ) ] (6) \mathcal{L}_{\mathrm{SAM}}= -\sum_{\mathbf{I} \in \mathcal{I}} \sum_{\mathbf{M} \in \mathcal{M}_{\mathbf{I}}} \sum_p^{H W}\left[\mathbf{M}_p \log \mathbf{P}_{\mathbf{M}, p}\right. \left.+\left(1-\mathbf{M}_p\right) \log \left(1-\mathbf{P}_{\mathbf{M}, p}\right)\right] \tag{6} L SAM = − I ∈ I ∑ M ∈ M I ∑ p ∑ H W [ M p log P M , p + ( 1 − M p ) log ( 1 − P M , p ) ] ( 6 )
Correspondence Loss :考虑到一个像素 p p p M I \mathcal{M}_{\mathbf{I}} M I M I p \mathcal{M}_{\mathbf{I}}^{p} M I p p 1 , p 2 p_1,p_2 p 1 , p 2 M I p 1 , M I p 2 \mathcal{M}_{\mathbf{I}}^{p_1},\mathcal{M}_{\mathbf{I}}^{p_2} M I p 1 , M I p 2
K I ( p 1 , p 2 ) = ∣ M I p 1 ∩ M I p 2 ∣ ∣ M I p 1 ∪ M I p 2 ∣ (7) \mathbf{K}_{\mathbf{I}}\left(p_1, p_2\right)=\frac{\left|\mathcal{M}_{\mathbf{I}}^{p_1} \cap \mathcal{M}_{\mathbf{I}}^{p_2}\right|}{\left|\mathcal{M}_{\mathbf{I}}^{p_1} \cup \mathcal{M}_{\mathbf{I}}^{p_2}\right|} \tag{7} K I ( p 1 , p 2 ) = ∣ M I p 1 ∪ M I p 2 ∣ ∣ M I p 1 ∩ M I p 2 ∣ ( 7 )
feature correspondence S I ( p 1 , p 2 ) \mathbf{S}_{\mathbf{I}}(p_1,p_2) S I ( p 1 , p 2 )
S I ( p 1 , p 2 ) = < F I , p 1 r , F I , p 2 r > (8) \mathbf{S}_{\mathbf{I}}(p_1,p_2)=<\mathbf{F}_{\mathbf{I},p_1}^r,\mathbf{F}_{\mathbf{I},p_2}^r> \tag{8} S I ( p 1 , p 2 ) =< F I , p 1 r , F I , p 2 r > ( 8 )
最后 correspondence loss 定义为:
L corr = − ∑ I ∈ I ∑ p 1 H W ∑ p 2 H W K I ( p 1 , p 2 ) S I ( p 1 , p 2 ) (9) \mathcal{L}_{\text {corr }}=-\sum_{\mathbf{I} \in \mathcal{I}} \sum_{p_1}^{H W} \sum_{p_2}^{H W} \mathbf{K}_{\mathbf{I}}\left(p_1, p_2\right) \mathbf{S}_{\mathbf{I}}\left(p_1, p_2\right) \tag{9} L corr = − I ∈ I ∑ p 1 ∑ H W p 2 ∑ H W K I ( p 1 , p 2 ) S I ( p 1 , p 2 ) ( 9 )
如果两个像素从来没有属于同一个分割的话,就令 K I = − 1 \mathbf{K}_\mathbf{I}=-1 K I = − 1
最后 SAGA 的 loss 为:
L = L S A M + λ L c o r r (10) \mathcal{L}=\mathcal{L}_{\mathrm{SAM}}+\lambda\mathcal{L}_{\mathrm{corr}} \tag{10} L = L SAM + λ L corr ( 10 )
3D Prior Based Post-processing 原始分割出来的 3D 高斯 G t \mathcal{G}^t G t 统计滤波算法 (Statistical Filtering) 和区域增长算法 (Region Growing) 。
Statistical Filtering :两个高斯基元之间的距离可以推断出他们是否属于同一个物体,统计滤波先用 K 最近邻 (K-Nearest Neighbors, KNN) 算法 计算每个高斯基元与最近的 ∣ G t ∣ \sqrt{|\mathcal{G}^t|} ∣ G t ∣ μ \mu μ σ \sigma σ μ + σ \mu+\sigma μ + σ G t ′ \mathcal{G}^{t'} G t ′
Region Growing Based Filtering :2D mask 可以作为目标正确位置的先验,首先将 mask 投影到分割出来的高斯基元 G t \mathcal{G}^t G t G c \mathcal{G}^c G c G c \mathcal{G}^c G c d g d_g d g
d g G c = min { D ( g , g ′ ) ∣ g ′ ∈ G c } (11) d_{\mathbf{g}}^{\mathcal{G}^c}=\min \left\{D\left(\mathbf{g}, \mathbf{g}^{\prime}\right) \mid \mathbf{g}^{\prime} \in \mathcal{G}^c\right\} \tag{11} d g G c = min { D ( g , g ′ ) ∣ g ′ ∈ G c } ( 11 )
找到欧拉距离的最大值 max { d g G c ∣ g ∈ G c } \max\{d_{\mathbf{g}}^{\mathcal{G}^c}|\mathbf{g}\in\mathcal{G}^c\} max { d g G c ∣ g ∈ G c } G t \mathcal{G}^t G t G c \mathcal{G}^c G c G t \mathcal{G}^t G t G c \mathcal{G}^c G c G c \mathcal{G}^c G c G t ′ \mathcal{G}^{t'} G t ′
Ball Query Based Growing :对于之前提到的问题 (ii),本文采用 ball query 算法从所有的高斯基元 G \mathcal{G} G G t ′ \mathcal{G}^{t'} G t ′ r r r G s \mathcal{G^s} G s r = max { d g G t ′ ∣ g ∈ G t ′ } r=\max\{d_{\mathbf{g}}^{\mathcal{G}^{t'}}|\mathbf{g}\in\mathcal{G}^{t'}\} r = max { d g G t ′ ∣ g ∈ G t ′ }
Reference [1]Segment Any 3D Gaussiansopen in new window