Feature Splatting-论文笔记
Feature Splatting: Language-Driven Physics-Based Scene Synthesis and Editing
ECCV 2024
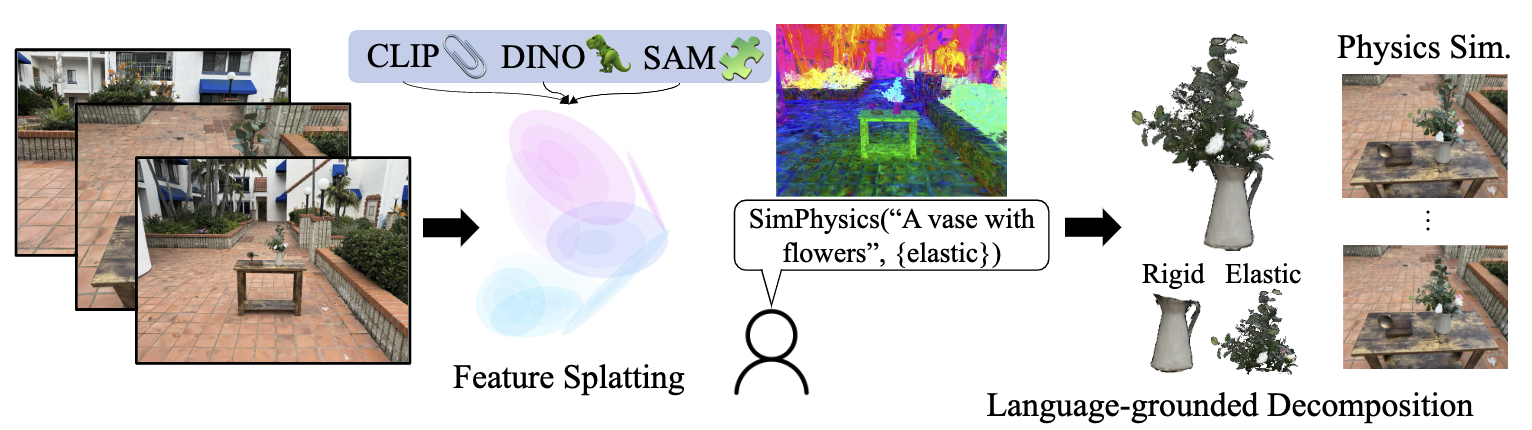
Abstract
使用 3D 高斯的场景表示法在静态和动态三维场景的外观建模方面取得了出色的效果。然而,许多图形应用需要同时处理物体的外观和物理特性。我们提出了 Feature Splatting,这是一种将基于物理的动态场景合成与基于自然语言的视觉语言基础模型的丰富语义相统一的方法。我们的第一个贡献是将高质量的、以物体为中心的视觉语言特征提炼为 3D 高斯特征,从而能够使用文本查询进行半自动场景分解。我们的第二个贡献是使用基于粒子的模拟器从静态场景中合成基于物理的动态效果,其中材料属性通过文本查询自动分配。我们对这一管道中使用的关键技术进行消融实验,以说明将外观、几何、材料属性和基于自然语言的语义统一表示为带特征的 3D 高斯所面临的挑战和机遇。
Introduction
本文的主要贡献:
- 提出了 feature splatting 这个新方法,通过对场景增加语义和语言驱动场景内的物体进行物理真实的移动,来增强静态场景。
- 一个基于 MPM 来驱动高斯的物理引擎,一种融合多个基础视觉 2D 模型的新分割方法。
- 证明 feature splatting 是一个优秀的语言驱动的场景编辑工具。
Method
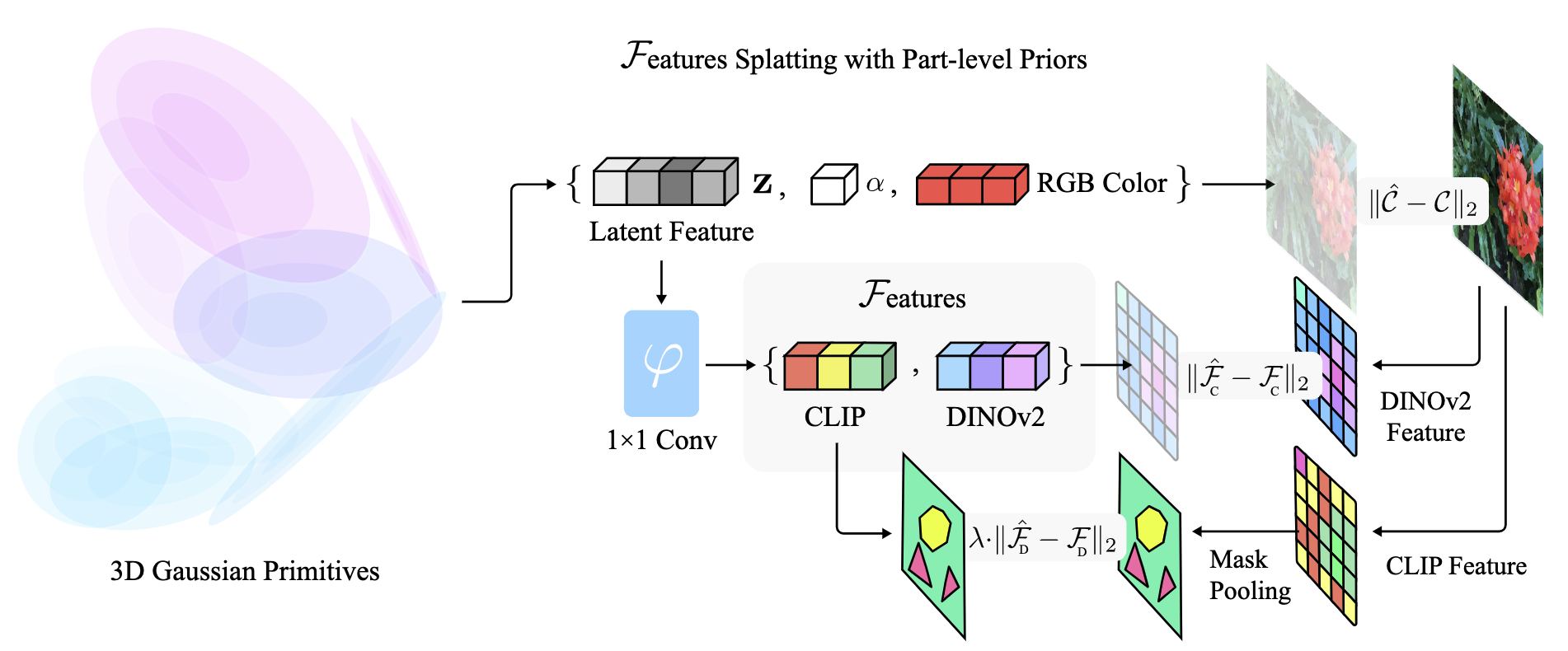
三个关键组件:
- 一个将丰富语义特征从视觉语言模型蒸馏到 3D 高斯的方法;
- 一个使用开放文本查询将场景分割为关键部分的方法;
- 一个通过语言来确定材料属性的方法 (作为物理真实动态场景合成的一部分);
Differentiable Feature Splatting
Feautre Splatting:对每个高斯基元增加一个额外的特征向量 ,与视角方向无关。然后进行渲染:
Systenms Considerations:直接光栅化高维度特征会导致昂贵的训练时间,深入分析后发现主要瓶颈在内存访问模式,通过设计了 cuda kernal 解决。
Improving Reference Feature Quality Using Part-Priors:CLIP 是用 2D 视觉模型获取语义特征,其中会包含一些噪声 (如图 3 所示),对于基于 NeRF 的模型来说直接用是没问题的,因为 NeRF 的连续表示是一种隐式的正则化。而对于高斯来说会过拟合,把噪声也当作语义特征。


本文用 DINOv2 和 SAM 的物体先验来提升高斯特征的质量。对于输入图像,首先用 SAM 获取 part-level masks (图 4c),然后对 和粗糙的 CLIP feature map 使用掩码平均池化 (Masked Average Pooling, MAP) 来聚合成单个特征向量:
是特征图中的像素坐标,然后将 分配给分割部分内的所有像素,如果一个像素属于多个部分,则该像素特征通过平均所有相关部分的特征来获得,这样就得到了图 4d。
为了进一步降低过拟合的可能性,本文提出了一个有两个输出分支的 shallow MLP,将 (图 2 Pipeline 中 那一部分) 作为中间特征。第一个分支为 DINO 特征 作为连续的 part-level 的语义 (如图 4e),第二个分支为 CLIP 特征 (图 2 中 和 应该是写反了)。
用 GT 图像的 SAM-enhanced CLIP 特征图和 DINOv2 特征图进行监督,最后整体的 loss 为:
DINOv2 的特征是作为一个平滑项对 CLIP 特征进行正则化,所以把 设置为 。
Todo
文章后面是语言驱动场景分割和语言驱动物理合成的部分,暂时先跳过。
Reference
[1]Feature Splatting: Language-Driven Physics-Based Scene Synthesis and Editing
[3]Learning Transferable Visual Models From Natural Language Supervision
[4]DINOv2: Learning Robust Visual Features without Supervision