HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors 项目地址open in new window
NeurlPS 2024
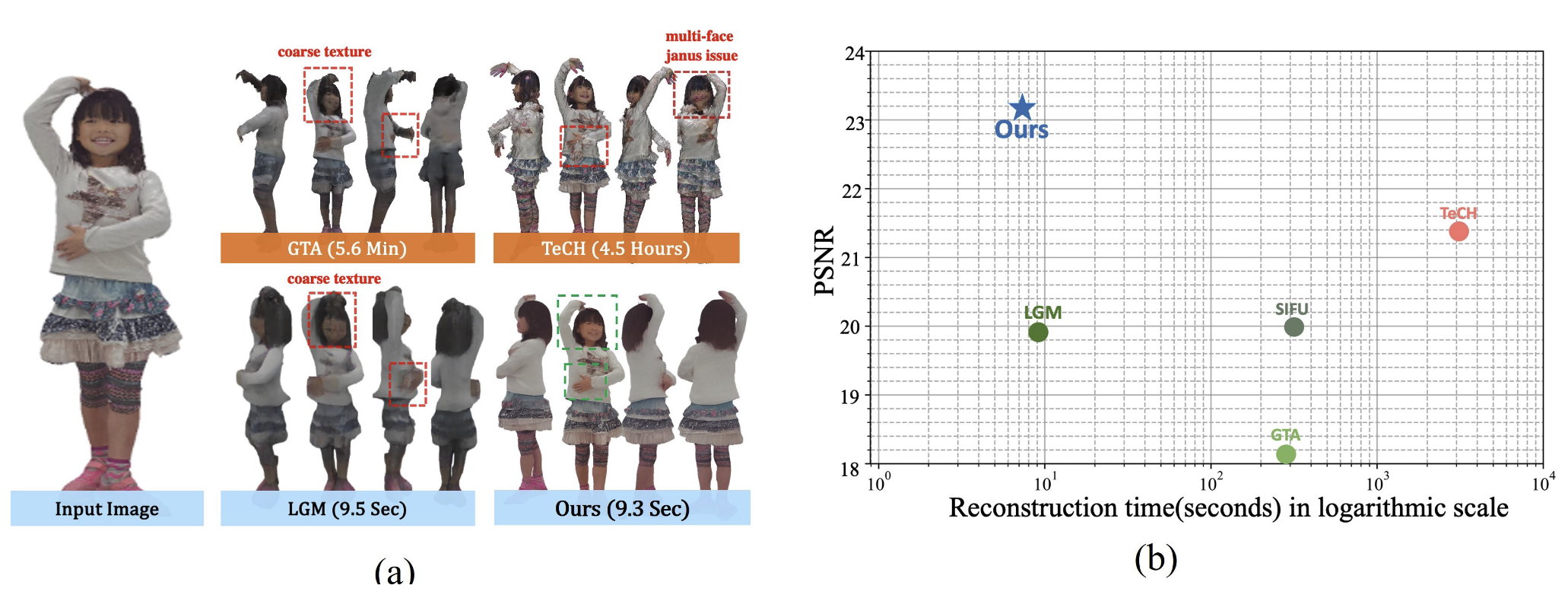
Fig. 1: Overview Abstract 尽管高保真人体重建技术取得了最新进展,但通常需要大量的输入图像或优化时间,这极大地阻碍了它们在更广泛的场景中的应用。为了解决这些问题,我们提出了 HumanSplat,它以生成的方式从单个输入图像预测任何人的 3DGS 属性。具体来说,HumanSplat 包括一个 2D 多视角扩散模型和一个具有人体结构先验的潜在重建 Transformer,能够巧妙地将几何先验和语义特征整合在统一框架中。此外,我们设计了一个分层损失,结合了人体语义信息,以实现高保真的纹理建模,并更好地约束估计的多视角。标准 benchmarks 和真实场景图像上的综合实验表明,HumanSplat 在实现逼真的新视角合成方面超越了现有的 SOTA。
Introduction 本文的主要贡献:
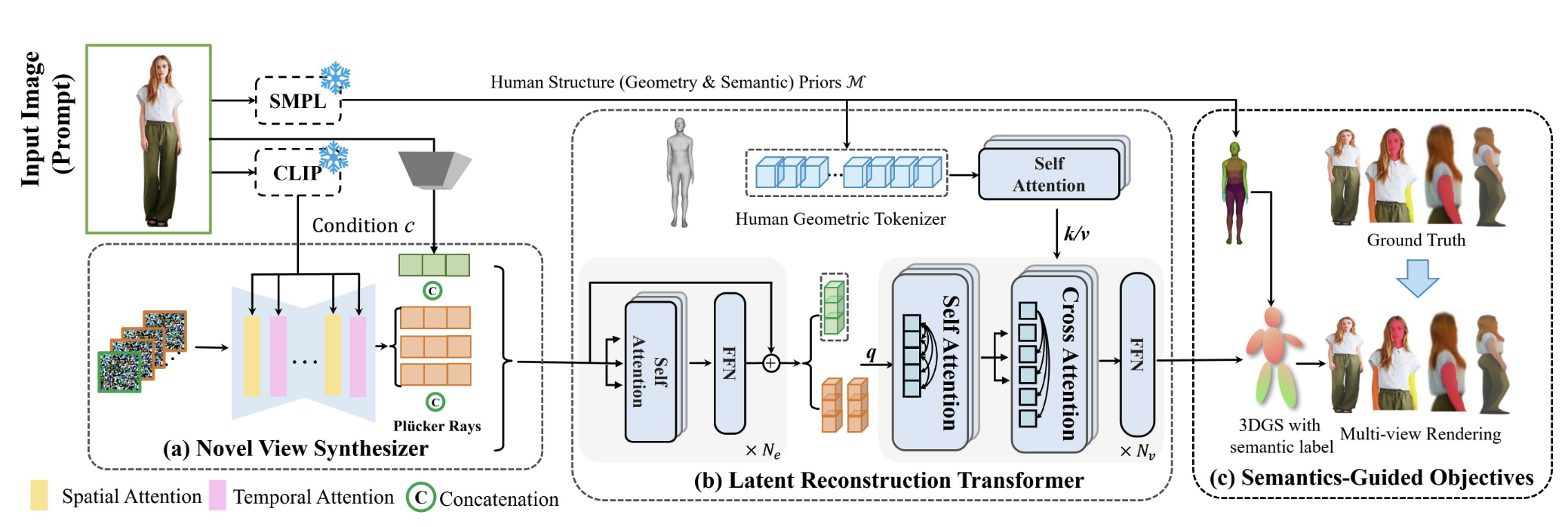
我们提出了一种新颖的可通用人体 GS 网络,用于从单张图像进行高保真人体重建 我们通过利用来自 SMPL 模型的人体几何先验和来自 2D 生成扩散模型的人体外观先验,将结构和外观信息整合到一个通用的Transformer框架中。几何先验有助于稳定生成高质量的人体几何结构,而外观先验则有助于推测穿衣人体的未见部分。 我们通过引入语义提示、分层监督和定制的损失函数,提升了重建人体模型的保真度。 Method Fig. 2: Pipeline Overview 首先先预测出人体 SMPL 模型的几何先验证 M \mathcal{M} M c \mathbf{c} c 视频扩散模型SV3Dopen in new window ——多视角生成器(novel-view synthesizer) 生成多视角的 latent features { F i ∈ R h × w × c } i = 1 N \{\mathbf{F}_i\in\R^{h\times w\times c}\}^{\mathbf{N}}_{i=1} { F i ∈ R h × w × c } i = 1 N N \mathbf{N} N h , w h,w h , w c c c latent reconstruction transformer 将人体几何先验和 latent features 集中在一个统一的架构内来预测高斯的属性 G : = { ( μ i , q i , s i , c i , σ i ) ∣ i = 1 , … , N p } \mathbf{G}:=\left\{\left(\boldsymbol{\mu}_i, \boldsymbol{q}_i, \boldsymbol{s}_i, \boldsymbol{c}_i, \boldsymbol{\sigma}_i\right) \mid i=1, \ldots, \mathbf{N}_{\mathbf{p}}\right\} G := { ( μ i , q i , s i , c i , σ i ) ∣ i = 1 , … , N p } N p \mathbf{N_p} N p
Video Diffusion Model as Novel-view Synthesizer SV3D 以通过 CLIP 得到输入图像 I 0 \mathbf{I}_0 I 0 c \mathbf{c} c VQ-VAEopen in new window E \mathcal{E} E I 0 \mathbf{I}_0 I 0 F 0 \mathbf{F}_0 F 0 UNetopen in new window D θ D_\theta D θ N N N { F i } i = 1 N \{\mathbf{F}_i\}^N_{i=1} { F i } i = 1 N
E ϵ ∼ p ( ϵ ) [ λ ( ϵ ) ∥ D θ ( { F i ϵ } i = 1 N ; c , F 0 , ϵ ) − { F i } i = 1 N ∥ 2 2 ] (1) \mathbb{E}_{\epsilon \sim p(\epsilon)}\left[\lambda(\epsilon)\left\|D_\theta\left(\left\{\mathbf{F}_i^\epsilon\right\}_{i=1}^{\mathbf{N}} ; \mathbf{c}, \mathbf{F}_0, \epsilon\right)-\left\{\mathbf{F}_i\right\}_{i=1}^{\mathbf{N}}\right\|_2^2\right] \tag{1} E ϵ ∼ p ( ϵ ) [ λ ( ϵ ) D θ ( { F i ϵ } i = 1 N ; c , F 0 , ϵ ) − { F i } i = 1 N 2 2 ] ( 1 )
{ F i ϵ } \{\mathbf{F}_i^\epsilon\} { F i ϵ } p ( ϵ ) p(\epsilon) p ( ϵ ) λ ( ϵ ) ∈ R + \lambda(\epsilon)\in\R^+ λ ( ϵ ) ∈ R + ϵ \epsilon ϵ 本文用人体数据集对 SV3D 进行微调以提升其在人体重建方面的能力。
Latent Reconstruction Transfomer Fig. 3: Illustration of latent reconstruction transformer 这一部分就是将从视频扩散模型中得到的 latent features 和人体几何先验集成在一起。
Latent Embedding Interaction 将输入图片的 latent features F 0 = E ( I 0 ) ∈ R h × w × c \mathbf{F}_0=\mathcal{E}(\mathbf{I_0})\in\R^{h\times w \times c} F 0 = E ( I 0 ) ∈ R h × w × c { F i ϵ } i = 1 N \{\mathbf{F}_i^\epsilon\}_{i=1}^\mathbf{N} { F i ϵ } i = 1 N
F ‾ 0 , F ‾ 1 , … , F ‾ N = FFN ( SelfAttention ( F 0 , F 1 , … , F N ) ) (2) \overline{\mathbf{F}}_0, \overline{\mathbf{F}}_1, \ldots, \overline{\mathbf{F}}_{\mathbf{N}}=\operatorname{FFN}\left(\operatorname{SelfAttention}\left(\mathbf{F}_0, \mathbf{F}_1, \ldots, \mathbf{F}_{\mathbf{N}}\right)\right) \tag{2} F 0 , F 1 , … , F N = FFN ( SelfAttention ( F 0 , F 1 , … , F N ) ) ( 2 )
普吕克坐标是用 6 维向量唯一表示 3D 空间中的一条线,具体是怎么表示可以看这篇文章open in new window 。每个像素对应相机发出的一条光线,有一个普吕克坐标。本质上就是相机位姿的特征图,把相机位姿作为 condition。
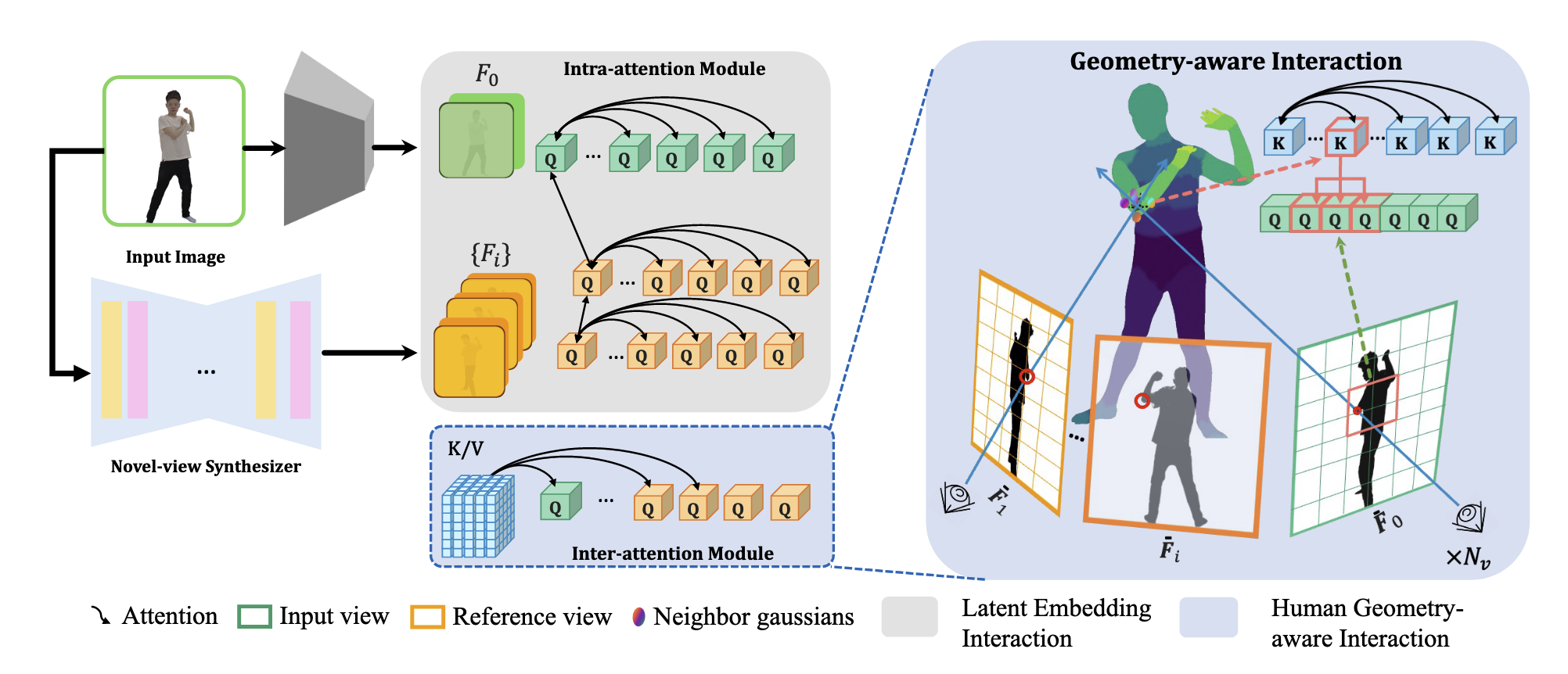
Geometry-aware Interaction Human Geometric Tokenizer. 这一部分是为了得到空间坐标 x ∈ R 3 x\in \R^3 x ∈ R 3 M ∈ R 6890 × 3 \mathcal{M}\in\R^{6890\times 3} M ∈ R 6890 × 3 x x x
Π i ( x ) = K ( R M i + t ) (3) \boldsymbol{\Pi}_i(x)=\mathbf{K}(\mathbf{R}\mathcal{M}_i+\mathbf{t}) \tag{3} Π i ( x ) = K ( R M i + t ) ( 3 )
R \mathbf{R} R t \mathbf{t} t K \mathbf{K} K 将 x x x F 0 ( Π ( x ) ) \mathbf{F}_0(\boldsymbol{\Pi}(x)) F 0 ( Π ( x )) H ˉ i ∈ R 6890 × d \bar{\mathbf{H}}_i\in\R^{6890\times d} H ˉ i ∈ R 6890 × d
Human Geometry-aware Attention.
通常直接使用 SMPL 模型作为先验是包含一定的误差的,因为 SMPL 不包含衣服的建模。为了解决人体先验方面的误差,本文将 3D tokens 投射到 2D 空间,然后查询 2D 空间到邻接窗口 (图 3)。具体来说,在 inter-attention 模块中引入 project-aware attention,在窗口 W ( k w i n × k w i n ) \mathbf{W}(k_{win}\times k_{win}) W ( k w in × k w in ) { F ˉ i } \{\bar{\mathbf{F}}_i\} { F ˉ i } { H ˉ i } \{\bar{\mathbf{H}}_i\} { H ˉ i }
F ~ i = FFN ( CrossAttention m a s k ( F ˉ i , H ˉ i ) ) (4) \tilde{\mathbf{F}}_i=\operatorname{FFN}(\operatorname{CrossAttention}_{mask}(\bar{\mathbf{F}}_i,\bar{\mathbf{H}}_i)) \tag{4} F ~ i = FFN ( CrossAttention ma s k ( F ˉ i , H ˉ i )) ( 4 )
只有当 Π ( H ˉ i , K , R , t ) \boldsymbol{\Pi}(\bar{\mathbf{H}}_i,\mathbf{K},\mathbf{R},\mathbf{t}) Π ( H ˉ i , K , R , t ) F ˉ i \bar{\mathbf{F}}_i F ˉ i O ( L F × L H ) \mathcal{O}(\mathbf{L}_F\times \mathbf{L}_H) O ( L F × L H ) O ( L F × k w i n 2 ) \mathcal{O}(\mathbf{L}_F \times k^2_{win}) O ( L F × k w in 2 ) L F \mathbf{L}_F L F L H \mathbf{L}_H L H
Semantics-guided Objectives 对于输出的 token F ~ i \tilde{\mathbf{F}}_i F ~ i 1 × 1 1\times1 1 × 1
Hierarchical Loss. 传统方法总是忽视人体包含的丰富的语义信息,本文提出了一个新的框架,利用语义线索、分层监督和定制的损失函数来指导训练过程。基于人体先验模型的丰富语义信息,建立起 3D 空间位置与人体部位之间的对应关系。因此,可以针对不同的身体部位使用不同的注意力权重,并从不同的视角渲染不同级别的 GT 图像以提供分层监督。这种方法极大地促进了基本身体部位的精确定位,包括头部、手和手臂。总损失定义为特定部分损失的加权和:
L H = 1 l 1 n ∑ i = 1 n ∑ j = 1 m λ i λ j L R e c ( I p a r t , j , I ^ p a r t , j ) (5) \mathcal{L}_{\mathcal{H}}=\frac{1}{l} \frac{1}{n} \sum_{i=1}^n \sum_{j=1}^m \lambda_i \lambda_j \mathcal{L}_{R e c}\left(\mathbf{I}_{\mathrm{part}, j}, \hat{\mathbf{I}}_{\mathrm{part}, j}\right) \tag{5} L H = l 1 n 1 i = 1 ∑ n j = 1 ∑ m λ i λ j L R ec ( I part , j , I ^ part , j ) ( 5 )
i ∈ { 1 , . . . , n } i\in\{1,...,n\} i ∈ { 1 , ... , n } j ∈ { 1 , . . . , m } j\in\{1,...,m\} j ∈ { 1 , ... , m } I ^ p a r t , j \hat{\mathbf{I}}_{\mathrm{part}, j} I ^ part , j I p a r t , j \mathbf{I}_{\mathrm{part}, j} I part , j j j j λ i \lambda_i λ i λ j \lambda_j λ j Reconstruction Loss. 基于 N r e n d e r \mathbf{N}_{render} N re n d er
L R e c = ∑ i N render L m s e ( I ^ i , I i ) + λ m L m s e ( M ^ i , M ) + λ p L p ( I ^ i , I i ) (6) \mathcal{L}_{R e c}=\sum_i^{\mathbf{N}_{\text {render }}} \mathcal{L}_{m s e}\left(\hat{\mathbf{I}}_i, \mathbf{I}_i\right)+\lambda_m L_{m s e}\left(\hat{\mathbf{M}}_i, \mathbf{M}\right)+\lambda_p \mathcal{L}_p\left(\hat{\mathbf{I}}_i, \mathbf{I}_i\right) \tag{6} L R ec = i ∑ N render L m se ( I ^ i , I i ) + λ m L m se ( M ^ i , M ) + λ p L p ( I ^ i , I i ) ( 6 )
I i \mathbf{I}_i I i I ^ i \hat{\mathbf{I}}_i I ^ i M i \mathbf{M}_i M i M ^ i \hat{\mathbf{M}}_i M ^ i L m s e \mathcal{L}_{mse} L m se L p \mathcal{L}_{p} L p Reference [1]HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priorsopen in new window
[2]SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image Using Latent Video Diffusionopen in new window
[3]Taming Transformers for High-Resolution Image Synthesisopen in new window
[4]Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasetsopen in new window
[5]普吕克坐标 Plücker coordinates 表示直线open in new window