ImmFusion-论文笔记
ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions
ICRA 2023
这篇论文用于机器人学课程 pre

Abstract
RGB 图像的 3D 人体重建在良好天气条件下能取得不错的效果,但在恶劣天气下效果会显著下降。作为补充,毫米波雷达已被用于在恶劣天气下重建 3D 人体 joint 和 mesh。然而,由于毫米波信号的稀疏性和 RGB 图像的脆弱性,将 RGB 和毫米波信号结合起来以实现全天候的鲁棒 3D 人体重建仍然是一个未解决的挑战。在本文中,我们提出了 ImmFusion,这是首个能够在各种天气条件下稳健地重建 3D 人体的毫米波-RGB 融合解决方案。具体来说,我们的 ImmFusion 包含图像和点云骨干网络用于特征提取,并包含一个 Transformer 模块用于特征融合。图像和点云骨干网络从原始数据中提取全局和局部特征,而融合 Transformer 模块则通过动态选择信息丰富的特征来实现两种模态的有效信息融合。在各种环境下捕获的大规模数据集 mmBody 上进行的大量实验表明,ImmFusion 能够高效利用两种模态的信息,实现稳健的全天候 3D 人体重建。此外,我们的方法在准确性上显著优于最先进的基于 Transformer 的激光雷达 - 相机融合方法。
Introduction
3D 人体重建广泛应用于许多实际的机器人应用中,例如人机交互、姿态估计和动作捕捉。目前,最流行的方法是使用 RGB 图像进行重建,然而,在恶劣环境下,使用 RGB 图像进行重建的性能仍然有限,因为 RGB 相机的感知能力在光照不良或恶劣天气条件下会迅速下降。另一方面,由于从单个图像回归深度本质上是一个病态问题,基于单目相机的 3D 重建相当复杂。
最近,毫米波雷达在无线感知领域越来越受欢迎,如自动驾驶、人类活动识别和无人机。同时,毫米波雷达在人体重建任务中表现出巨大的潜力,因为它不受不利环境的影响。因此,在某些特定情况下,其重建结果与 RGB 图像相比具有竞争力或优越性。然而,尽管毫米波信号具有深度测量和抗极端天气条件的能力,但毫米波重建受限于稀疏性和多径效应,限制了其在正常场景中的高性能。将 RGB 信号引入毫米波系统可能是一个解决方案,融合这两种模态以结合它们的优势应该是实现全天候鲁棒 3D 人体重建的关键。
大多数现有的激光雷达 - 相机融合方法采用点到图像投影,通过逐元素加法或通道连接来融合点云和RGB像素值。然而,直接将稀疏、噪声、随机丢失和时间闪烁的毫米波点云附加到RGB图像上会降低提取的特征,特别是在光照不良等恶劣环境下。因此,这种策略不适用于毫米波 - RGB 融合。另一方面,Transformer 为多模态融合方法的研究开辟了新途径。然而,这些 Transformer 融合框架主要集中在基于激光雷达 - 相机融合的目标检测上,这对于基于毫米波 - RGB 融合的人体重建任务并不适用。
为了解决这些问题,本文提出了 ImmFusion,这是第一个结合毫米波点云和 RGB 图像以鲁棒地在各种天气条件下重建 3D 人体的融合解决方案。鉴于多径效应引起的背景噪声,我们从点簇而不是单个点中提取特征。此外,为了解决异构模态的时空错位问题,我们通过一个设计精巧的融合 Transformer 模块,利用局部和全局特征来融合密集的图像特征和稀疏的雷达点簇特征。
本文的主要贡献:
- 提出了ImmFusion,这是第一个在包括雨、烟雾和光照不良等严酷环境在内的所有天气条件下进行 3D 人体重建的最先进毫米波 - RGB 融合方法。
- 采用了一个设计精巧的融合 Transformer 模块,有效地融合了从毫米波和 RGB 模态提取的全局和局部特征,并设计了一个巧妙的模态屏蔽模块,以增强模型在所有场景中的鲁棒性。
- 在大规模毫米波数据集 mmBody 上评估了 ImmFusion,结果表明在所有天气条件下,ImmFusion 的表现均优于其他非融合或激光雷达 - 相机融合模型。
Method
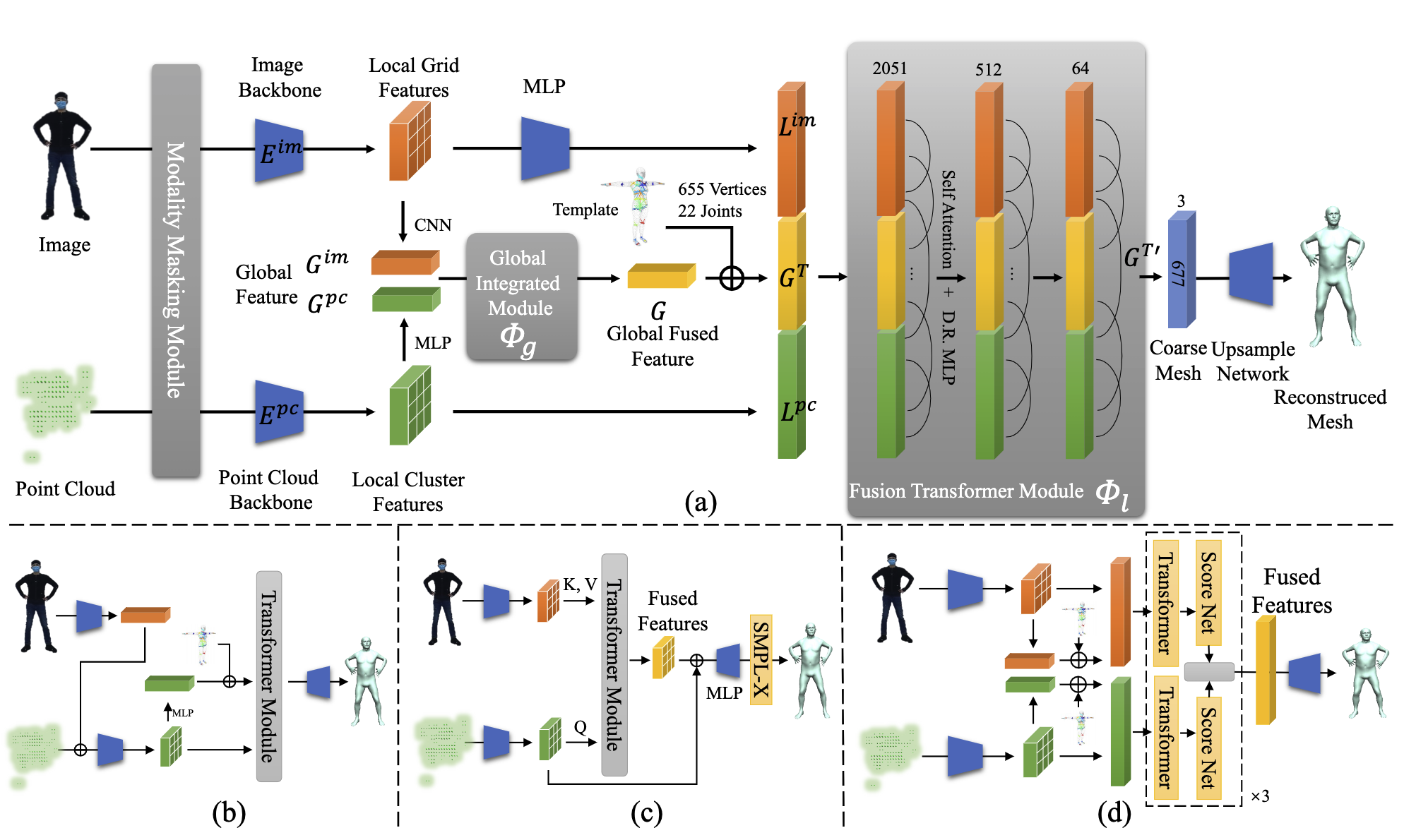
图 2 展示了本文的 pipeline,给定一个具有固定点数的雷达点云和一个大小为 的图像,首先由图像和点云 backbone 分别提取全局/局部点和图像特征。接下来,将两个全局特征合并为一个全局特征向量,并嵌入 SMLP-X 模板位置。然后,将所有全局/局部特征标记为多层融合 Transformer 模块的输入,以动态融合两种模态的信息,并直接回归 3D 人体 joint 和粗略 mesh 顶点的坐标。最后,使用 MLP 从粗略 mesh 顶点上采样到完整的 SMPL-X mesh 顶点。
Preliminary of 3D Human Body Reconstruction
3D 人体重建旨在预测所有关节和顶点的 3D 位置。本文采用非参数方法进行人体重建,使用从 GT 中自动标注的 bounding box 来裁剪仅包含身体部分的区域。给定一个数据集 ,其中 是裁剪后的毫米波雷达点云 (含 1024 个点), 是大小为 的 RGB 图像的人体区域, 分别是 时刻 GT 标注的 22 个关节和 10475 个顶点的位置,我们努力融合两种模态的输入信息来重建 3D 人体。
Extraction of Global and Local Features
之前点级融合工作是直接连接图像特征或将 RGB 像素投影到点云上,作为基于点云的模型的扩展特征,如图 2(b) 所示。因为毫米波雷达点的稀疏性和噪声问题,这种融合策略并不适用于毫米波 - RGB 融合,随机丢失和时间闪烁等问题会导致获取更少甚至错误的图像特征。此外,在光线不足等不利环境下,图像特征的低质量会严重降低模型的性能。由于不同身体部位的图像特征质量不平衡,不同关节的重建误差显著不同。
因此,本文建议融合图像特征和点特征,以提高整个身体的精度。本文为图像和点云输入提取全局和局部特征,以帮助提取全局上下文依赖关系并建模局部交互。具体来说,直接将点云和图像输入常用的点云和图像的 backbone 网络,以提取全局和局部特征。
对于点云数据,本文使用 PointNet++ 从雷达点云 中获取簇特征 ,其中 32 表示最远点采样 (Farthest Point Sample, FPS) 算法中种子采样点的数量,3 表示空间坐标,2048 表示从分组局部点提取的特征维度。使用 MLP 进一步从簇特征 中提取全局特征向量 。对于图像数据,本文使用 HRNet 获取全局特征 和 grid 特征 (使用 MLP 使 HRNet 的特征与点特征相同)。
这两个全局特征通过全局集成模块 (Global Integrated Module, GIM) 实现融合,GIM 由一个小型 Transformer 模块实现:
将人体模板 mesh 中每个关节和顶点的3D坐标附加到全局向量上来进行位置编码:
-
两种局部特征的目的是为人体重建提供细粒度的局部细节。
Transformer Fusion with Global and Local Features
本文采用多头注意力机制来缓解由于毫米波信号的稀疏性和噪声以及在极端条件下RGB信息不足所导致的特征退化。利用融合 Transformer 模块 来结合雷达点云和图像的优势,使模型能够动态选择两种模态中信息丰富的特征:
-
-
在关注有效特征并限制不良特征的同时,融合 Transformer 模块 自适应地在从全局特征 生成的关节/顶点 query 和来自局部特征的点/图像 token 特征 、 之间采用交叉注意力来聚合相关的上下文信息。同时,自注意力机制推理每对候选 query 之间的相互关系。然后用图卷积将包含丰富跨模态信息的 query 解码为关节和顶点的 3D 坐标。最后,使用 MLP 实现的线性投影网络从粗略输出的 mesh 上采样到原始的 10475 个顶点。
Distortion solution by Modality Masking
尽管多头注意力机制具有优越性,但由于训练数据的偏差 (没有包含不利条件下的数据),模型在传感器失真情况下容易表现不佳,这使得 Transformer 在我们的实验中倾向于将所有注意力集中在正常情况下表现更好的单一模态上。为了有效激活模型在一般场景下的适应性,我们设计了一个模态屏蔽模块 (Modality Masking Module,MMM),以随机屏蔽一个输入模态,从而强制模型在各种情况下从另一模态中学习。结果表明,MMM 使融合 Transformer 模块能够克服训练数据偏差问题,并考虑两种模态,从而在我们的实验中进一步促进模型在所有场景下的表现。除了模态屏蔽,我们还随机屏蔽了一些输入 token 特征的百分比,以模拟自身或烟雾遮挡和缺失部分。
Reference
[1]ImmFusion: Robust mmWave-RGB Fusion for 3D Human Body Reconstruction in All Weather Conditions